seL4 是目前全球最具安全保证的操作系统内核之一,其“高安全保证”主要来自形式化验证。这意味着通过数学证明确保内核的设计和实现满足严格的安全和可靠性要求。这一特性使 seL4 成为航空航天、国防、汽车和工业控制等对安全性要求极高的领域的理想选择。
![]()
seL4 峰会是由seL4基金会主办的一年一度的的国际性峰会,专注于seL4微内核——全球最具安全保证的操作系统内核,同时涵盖所有与seL4相关的技术、工具、基础设施、产品、项目和人员。它的宗旨是聚集整个seL4社区,共同学习、分享和交流:
- 了解seL4技术、最新进展、应用情况、成功案例、面临的挑战以及未来规划;
- 分享最新的seL4开发、研究成果、经验以及在现实世界中的应用;
- 帮助seL4开发者、用户、供应商、客户、支持者、潜在合作伙伴及爱好者建立联系。
2023年seL4峰会于2023年9月19日至21日在美国明尼阿波利斯的Elliot Park Hotel举行,由 Linux 基金会主办。Google Research 团队发表了介绍 CantripOS 的其中一个 Keynote 演讲。主要演讲者为 Sam Leffler , 幻灯片作者为:June Tate-Gans (Google), Sam Leffler (Google), Kai Yick (Google),开篇的时候也提到了 Fuchsia。


活动上 CantripOS 的介绍是:
CantripOS 是一个开源操作系统,专为在嵌入式系统上运行机器学习工作负载而设计。它作为谷歌项目 Sparrow 的一部分进行开发,该项目旨在构建一个面向安全和隐私、低功耗的嵌入式平台,用于机器学习应用。CantripOS 采用 Rust 编程语言开发,运行在 seL4 微内核之上,并使用了经过修改的 CAmkES 框架。这使得 CantripOS 能够在受控的沙盒中动态加载应用程序,同时依然保留静态设计系统的优势。本文描述了系统设计、对 seL4 和 CAmkES 的修改以及未来的发展方向。所有提到的工作均已在 GitHub 上公开。
下面 Fuchsia 社区整理的演讲的中文主旨(第一人称,使用AI工具撷取并粗略调整),幻灯片来自 seL4 Summit 官网,未作修改,文尾附相关链接,请注意,下面中文内容可能包含大量错误,仅供感兴趣的同学参考用,建议观看文尾附着的 YouTube 原始英文视频。 请注意一些常见的听错的关键词:比如 CAmkES 发音有点像 campus 校园, RPC 容易听成 IPC 等等。本文会不断更新不断完善,也欢迎社区专长的朋友跟我们联系,帮我们一起完善。

我真的很兴奋,今天Kai和Sam会为我们做主题演讲。他们俩都是谷歌的人,Kai是硬件经理,Sam是软件工程师。他们要聊聊他们正在开发的 CantripOS,我对此非常期待,所以我就不多说了,留给他们来分享吧。好的,大家好,早上好。在这里先说一下,我今天早上还没喝咖啡,所以如果我搞错了,Sam会帮我补充的。既然这样,我们就开始吧。

关于 CantripOS,它是谷歌一个更大项目的一部分。我会花几分钟时间来介绍一下我们称之为 Project Sparrow 的宏观介绍。接着,我们会聊聊我们组装在一起的匹配系统,这个 CantripOS 就是在这个系统上运行的。显然,之后我们还会深入讨论 CantripOS,并谈谈我们在这个领域的未来工作。嗯,开始吧,谷歌是一家以人工智能为主的软件公司。

“我们为我们的设备生态系统提供服务,包括从自家品牌的 Pixel 设备出发,还有其他相关品牌的东西。此外,还有我们的 生态系统,Android, Fuchsia, 还有大家应该都听说过 Pigweed,它是我们嵌入式的操作系统,适用于从耳机到各种其他设备。随着人工智能的创新加速,我们的系统也正从我们所谓的 ML 2.0 世界走向 3.0。”

随着基于变压器的模型和大型语言模型的发展,我们正在逐步摆脱传统的CNN架构,转向使用分词器和大型模型等等。我们开始意识到,这里面有很多挑战正在变成我们在提供体验时的限制,比如大多数摩尔定律的时间可能快到了,我们不能再指望每隔几年晶体管的数量会翻倍或四倍。而电池技术方面,情况也不是特别乐观。
“为了支持一些新兴的机器学习应用,这方面的发展速度非常快。同时,实际上也面临着一些安全挑战,尤其是在隐私方面,尤其是涉及到用户信息和数据时。显然,随着人工智能技术的迅速发展,能够支持这些技术的系统变得非常具有挑战性,因为计算需求呈指数增长,而且运行这些模型的复杂性也在增加。”好的,现在你知道了,我们的设备在达到热功率极限的时候,会让能耗显著提高。为了提供更好的体验,我们实际上已经达到了这个极限。所以,如果不能依赖我之前提到的那些东西,我们就必须真正从系统的整体设计出发,来优化,而不仅仅是从加速器的角度来看,尝试提取每一丝潜力。这段话要说的是:我们可以从系统中获取能量,以实现让体验成为可能的目的。

代码设计是我们从硬件和软件两个方面来实现这个目标的一种方法,还涉及到编译器的角度,以确保这些工作负载能比较好地映射到设备上。当然,安全和隐私也是非常重要的因素。随着这些模型越来越先进,个性化用户模型的趋势也在不断增强,包括个性化和生成式AI。信任、安全性和透明度也是重要的方面。“可爱程度和隐私保护是我们在未来几年内想要优先实现的目标,特别是因为用户需要信任他们的数据是安全的,隐私是受到尊重的。你也知道,鉴于欧洲正在加强监管,甚至在某些情况下禁用这些大型模型,确实是个明显的担忧。我们也在考虑很多解决方法,当然,透明性和可审计性也是必不可少的。”

“这其中的一种,还有其他技术手段可以展示我们如何尽可能确保用户信息的安全,既包括设备层面,也包括从设备到我们数据中心的模型层面。那么,什么是Project Sparrow呢?Project Sparrow是一个开源项目,目的是加速安全、可扩展和高效的机器学习系统及其子系统的发展。这是一个开源组件的集合,旨在快速原型设计、系统探索和共同设计这些新一代生成式人工智能系统。这个项目由谷歌主导,我们还没完全公布,预计在11月的时候会有更多消息。项目得到了多家公司、学术界以及其他组织的支持。我们的目标是加速开发和基础设施建设,以支持下一代更安全的应用生态系统。
“这显然是为了启用新的应用场景,减少开发和部署的时间,同时尽可能透明,无论是在系统的开发还是部署方面。抱歉,我刚才没赶上幻灯片的节奏, blame it on coffee。不过在进入我们做的共创过程之前,我会更加认真地按按钮。很多人问我们……”知道开发开源软件很不错,但开源硬件可就不一样了,因为没有人会花几百万美元去把 GitHub 上的开源代码拿过来,按在硬件上。所以,我们之前说的,策略上我们会在代码开发过程中和知识产权提供方合作,这样在需要进行采纳的时候,就能真正做好准备。而任何我们从系统软件到硬件共同设计的东西,都会考虑到这一点。
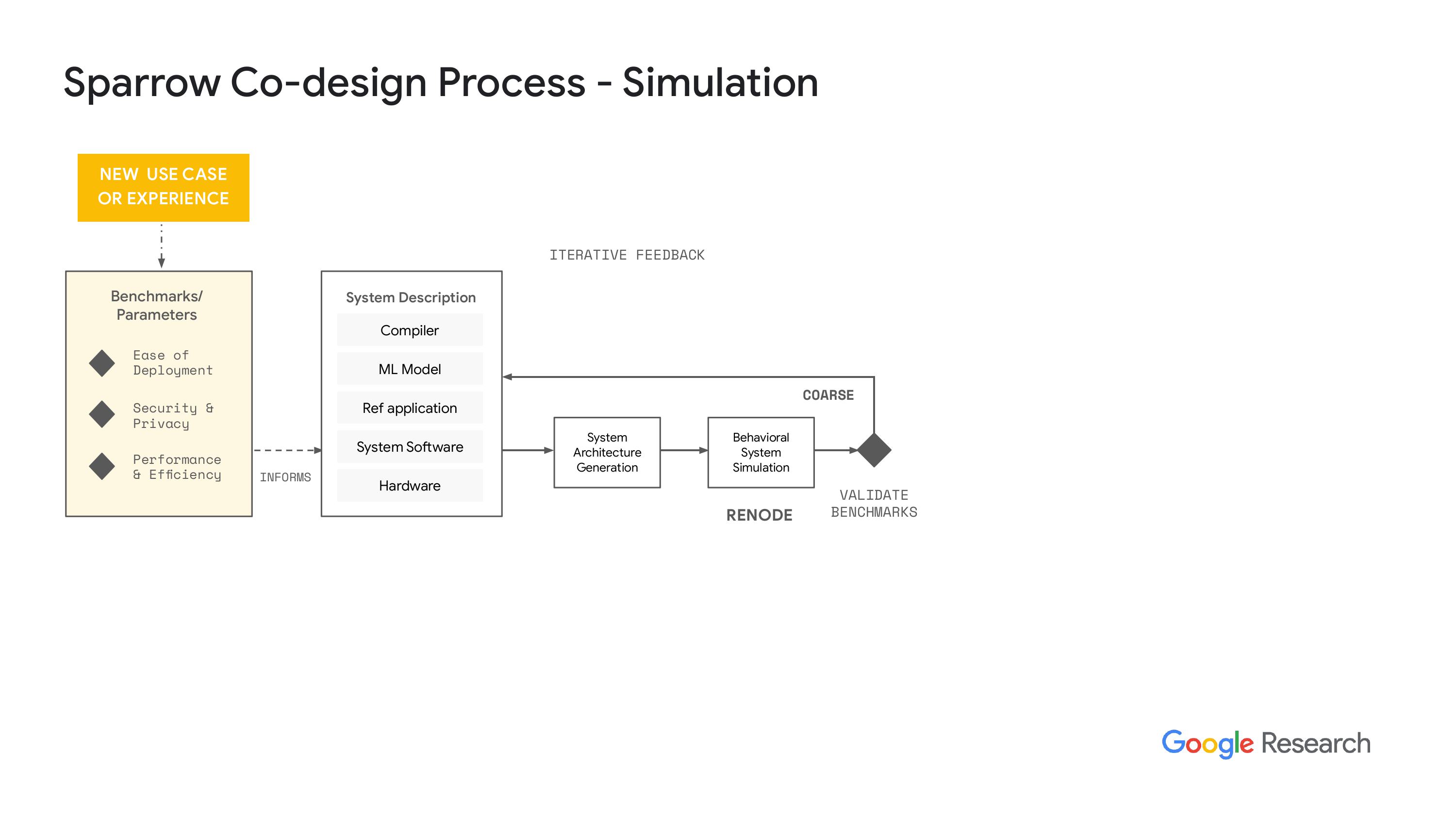
“这将是一个大家共同合作的事情,并且也会由提供方来支持,因为我们其实并不打算专注于硬件方面。这听起来应该不算新鲜事吧?我们希望能让大家有能力去做这件事,并通过这个过程来盈利。回到共同设计的这个过程,显然我们都是从CJ或者KPI开始,或者是我们想要实现的新体验。”
“我们制定了一套指标和基准,希望能达成这些目标。然后我们会生成一个系统描述。我们希望把一切都自动化,但显然是不可能的。所以有些系统描述将会用于工程工作,从编译器的角度来看,我们希望为处理器和加速器等添加自定义指令。这些内容会被整合到系统中,其他部分则会流向机器学习模型,比如我们如何进行量化,如何利用稀疏性,此外,我们还会生成一些参考应用,以便更清楚地表达这些内容。”
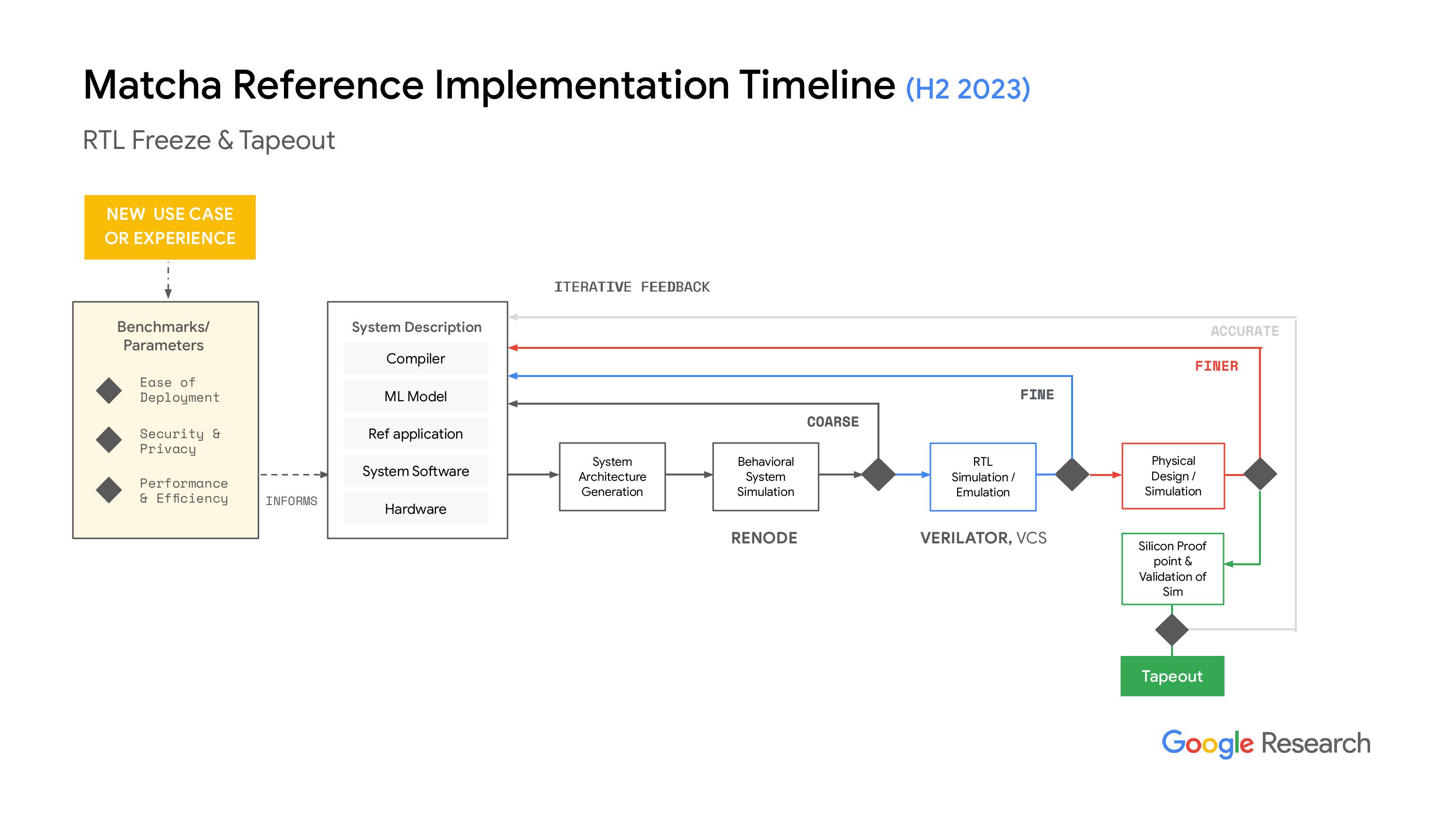
"传感器数据是怎么进来的,然后通过机器学习加速器又是怎么加速处理的,对吧?然后,我们又会怎么使用这些结果,显然,系统软件也是很重要的。所有这些东西是怎么协同工作的,以确保我们的系统和硬件都很安全。硬件是一个半自动化的地方,所以我们可以用HJ来描述这个系统,很多技术都是来源于开放泰坦项目,大家都知道开放泰坦这个努力,对吧?好极了,所以我们就利用了同样的技术。"这段话的大意是:他们用来描述系统的基础设施,比如设置一组IP地址、互联互通的方式,以及这些元素如何组合成一个参考设计。显然,我们有工具可以处理这些H JSON文件,并生成一个系统架构模型,这个模型能输入到我们的行为模拟器中。在行为模拟器中,我们与微型人工智能团队合作,使用了相关工具。"io 是他们开发的一个框架,利用 St 和我觉得,呃,微芯片,基本上是用来标记和模拟他们的 SoC,我想应该是微控制器吧,还有基于这些芯片构建的系统,从电路板的角度来看。我们能够将系统描述转化为行为模拟器的模型,而这个行为模拟器有一套指标,从性能计数器到,呃,显然自动测量安全性非常困难,甚至可以说是不可能的,但在实际操作方面…"
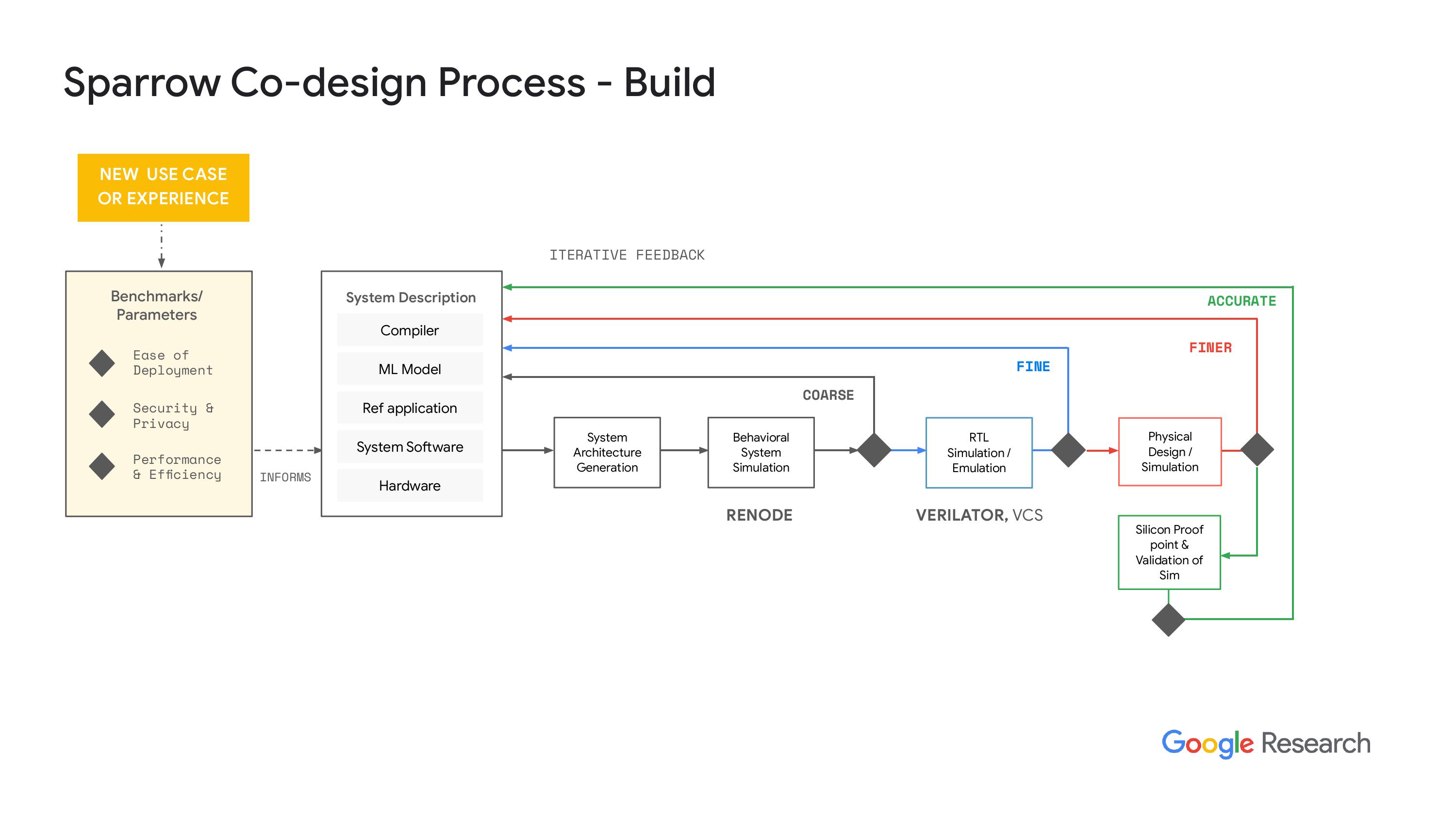
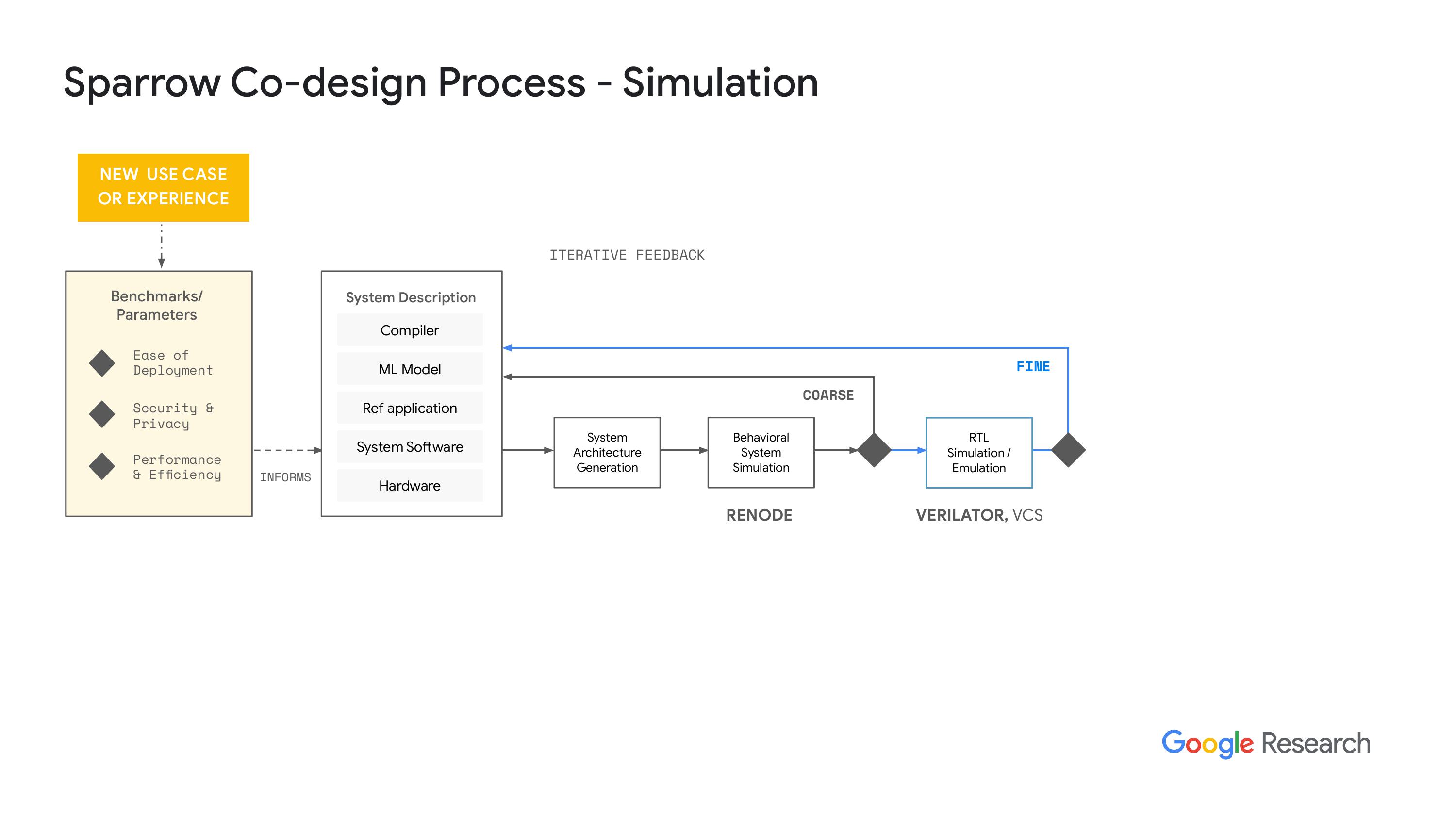
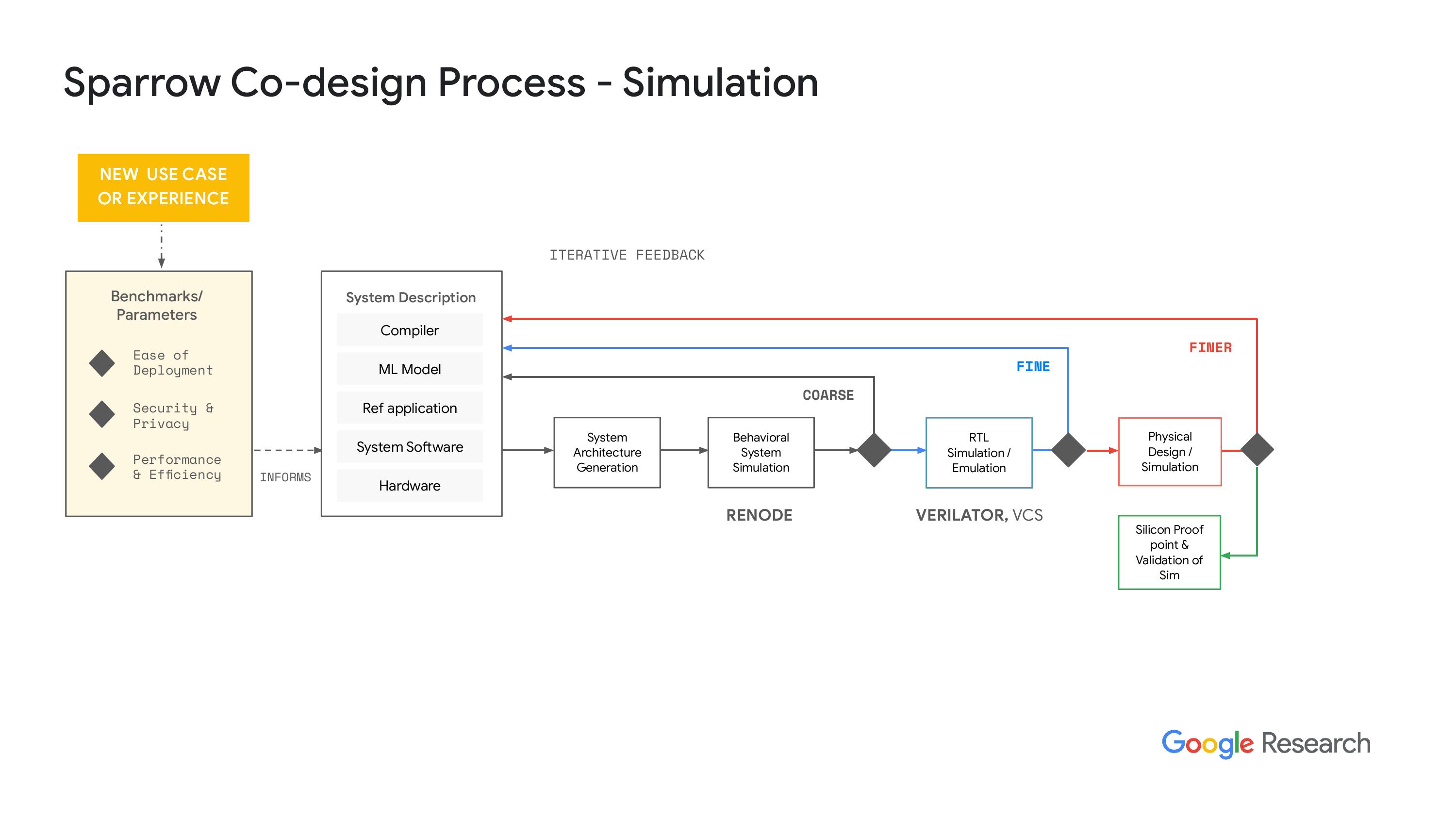
“系统性能方面,我们可以从两个方面获取数据,一个是循环次数,另一个是关于功耗性能和潜在芯片结果的初步估算。这些数据都是基于假设这个芯片是独立的,而不是某个子系统的。我想我们也可以从子系统获得数据,但我们还没有试过。不过,核心思想是要快速失败,对吧?我们想尽可能快地迭代这个过程。如果发现了有趣的结果,我们就可以继续推进。”下一步,我们进入RL模拟,实际上我们使用的是vator,哦,抱歉,其实是VCS。我们要确保vator的结果和预期一致。这个过程的最终结果需要一些时间。而且,当我们进入物理设计时,所需时间会更长,但结果会更加准确。我们会用我们的系统软件进行整个系统的模拟,不过大多数时候都得直到第二天才能看到结果,因为这个模拟过程耗时很长。不过,结果会更好。显然,当我们对结果感到满意时,我们就会和我们的合作伙伴一起生成硅证明点,或者说是一个结果,然后我们可以把硅作为测试芯片,来验证我们的仿真工具,确保我们做的事情是对的,并且数据和仿真结果是相关的。是的,目前我们希望整个流程都能完全开源。公司内部还有其他团队在推动和赞助这一工作。
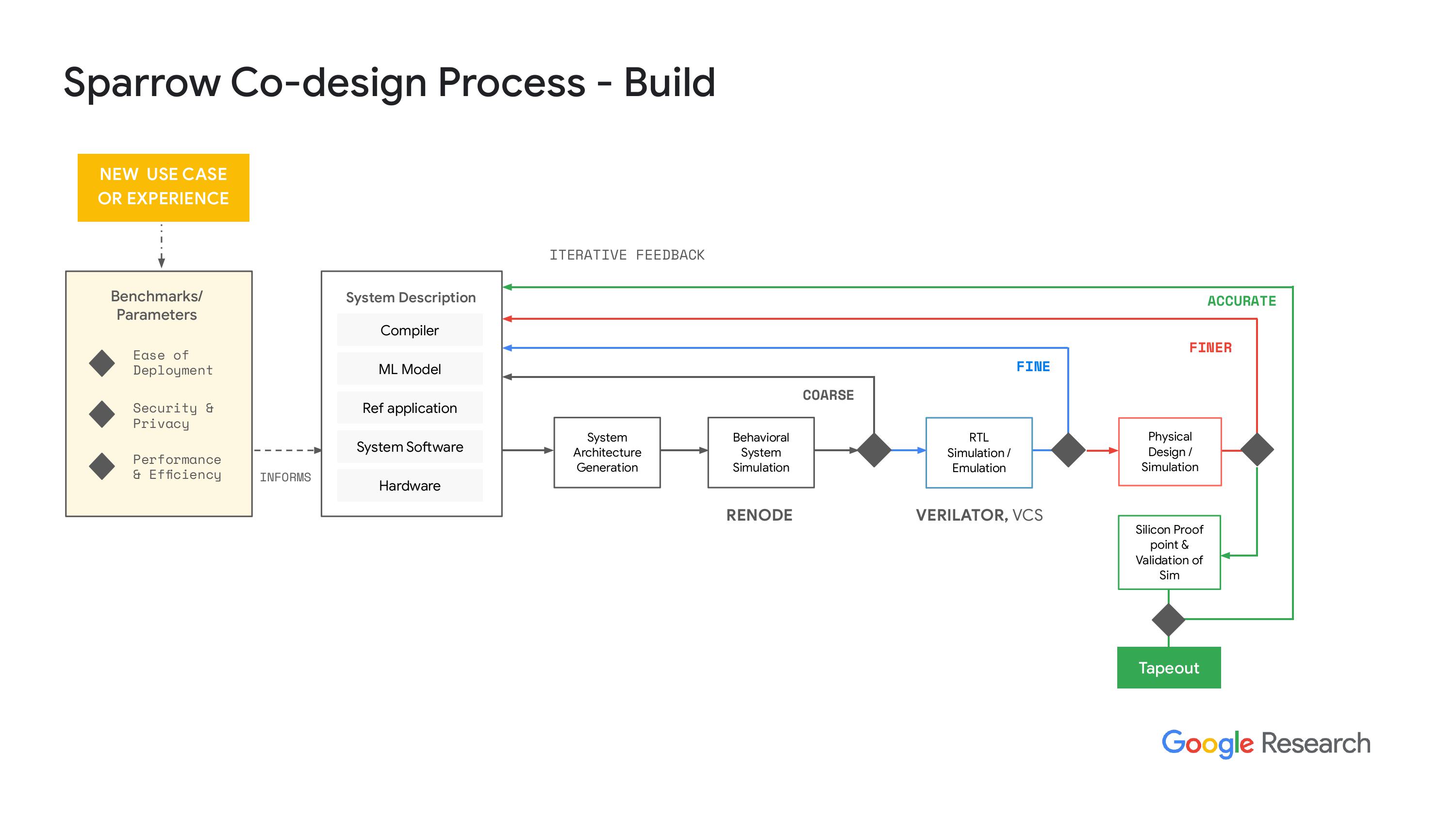
“关于开源的路和天空水之类的努力,我们还没有把所有这些东西整合进来,主要是因为风险的问题。我们正在和一家做硅的公司合作,不能一下子就让他们转向开源工具,尤其是在后端方面。所以我们正在努力,希望能在2024年或2025年做到这点。但目前我们还是在用设计编译器和其他一些工具,把RTL仿真层转到物理层。”
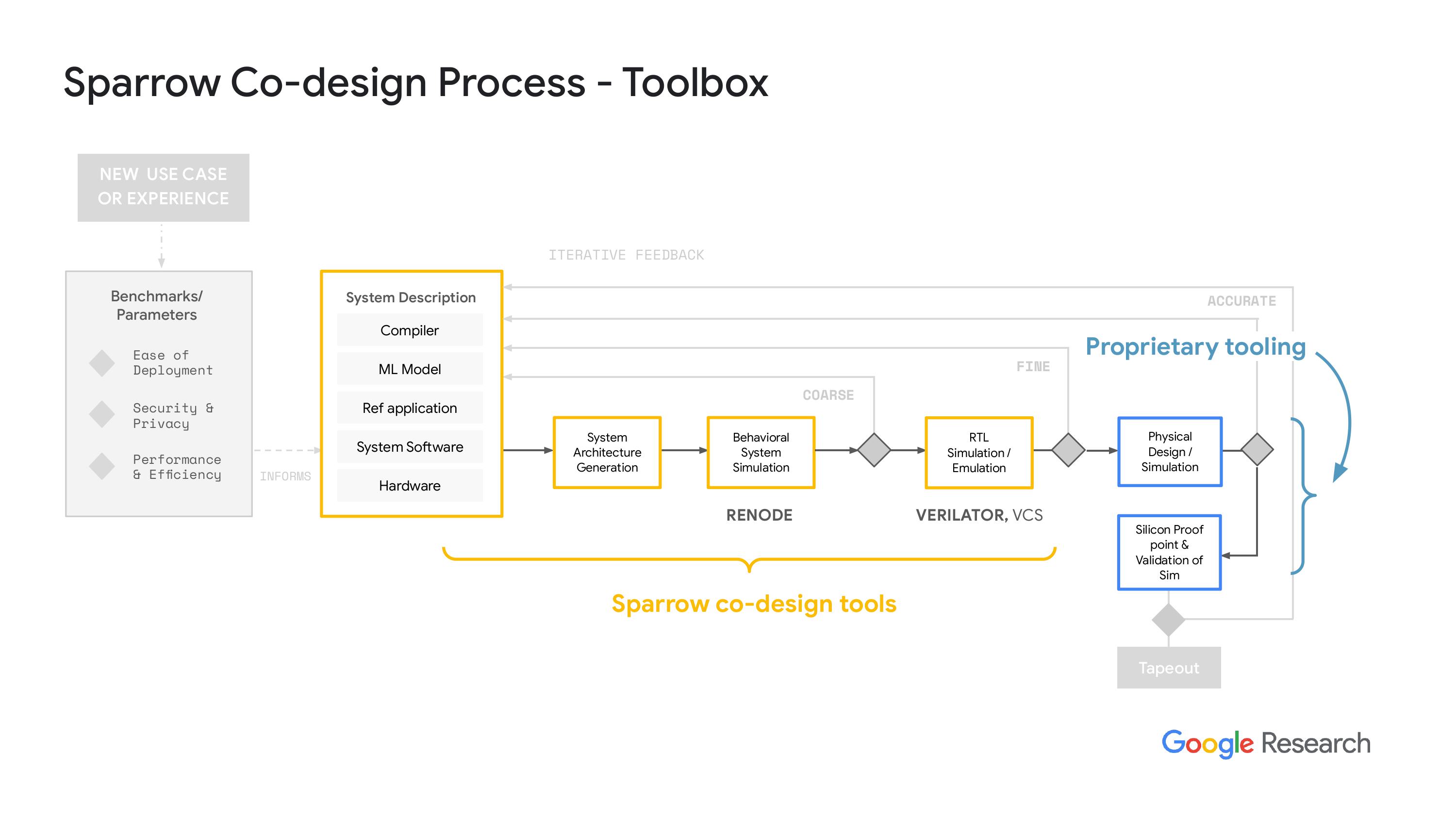
“另外就是 Matcha 系统呢?我们把工具、一些知识产权、技术和软件结合在一起,需要一些东西来追求。我们想展示一下其实可以生成一个有效的系统,而且是在机器学习的框架下。”
“我们这种环境有点像模型的级联架构,把所有传感器的输入进行标记,然后发送到我们称之为‘髓质’的决策路由机制,决定是把数据输入到本地语言模型还是数据中心的语言模型。我们想解决一些更具体的问题,所以我们专注于标记器和支持机器学习的部分。”

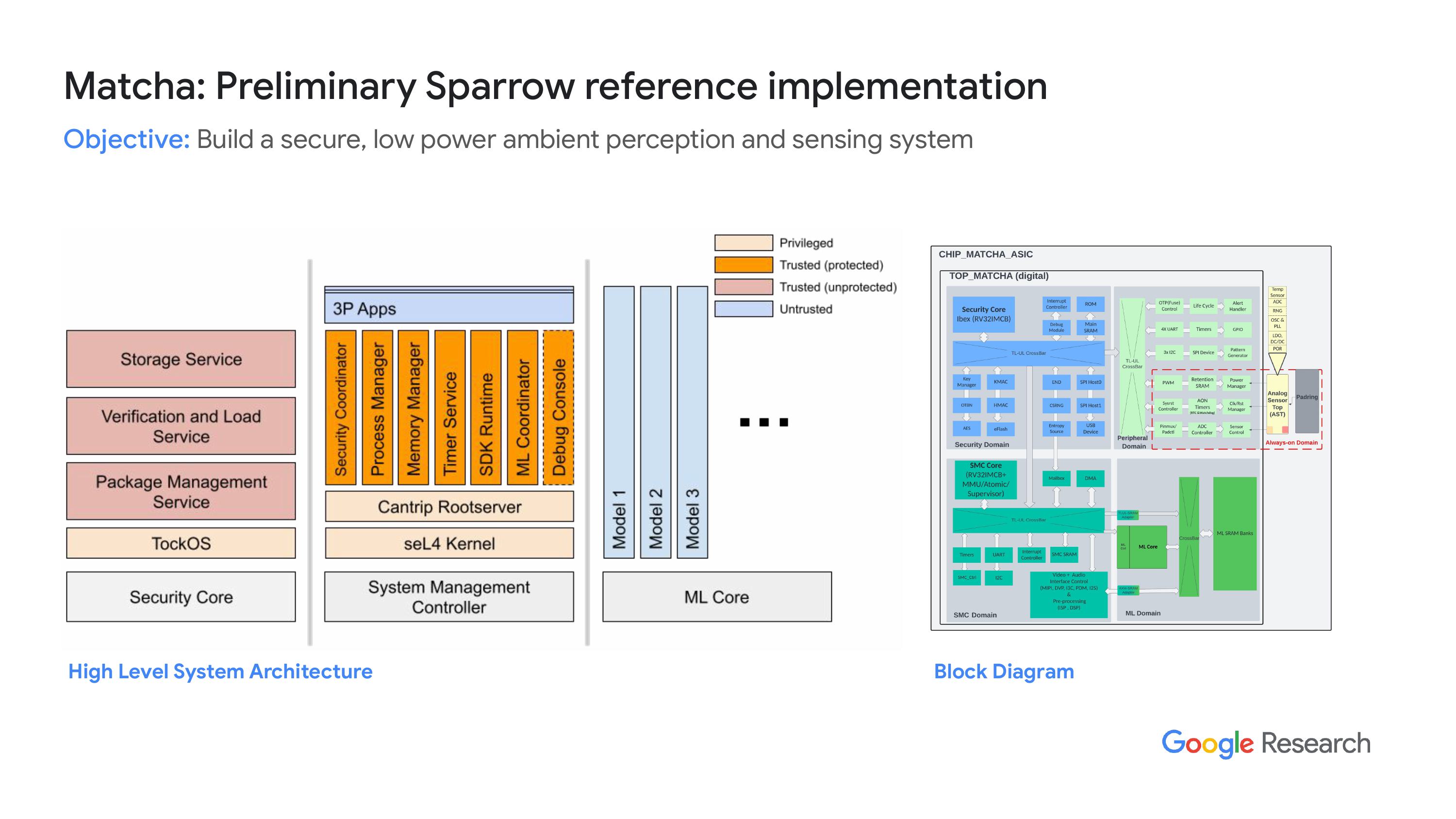
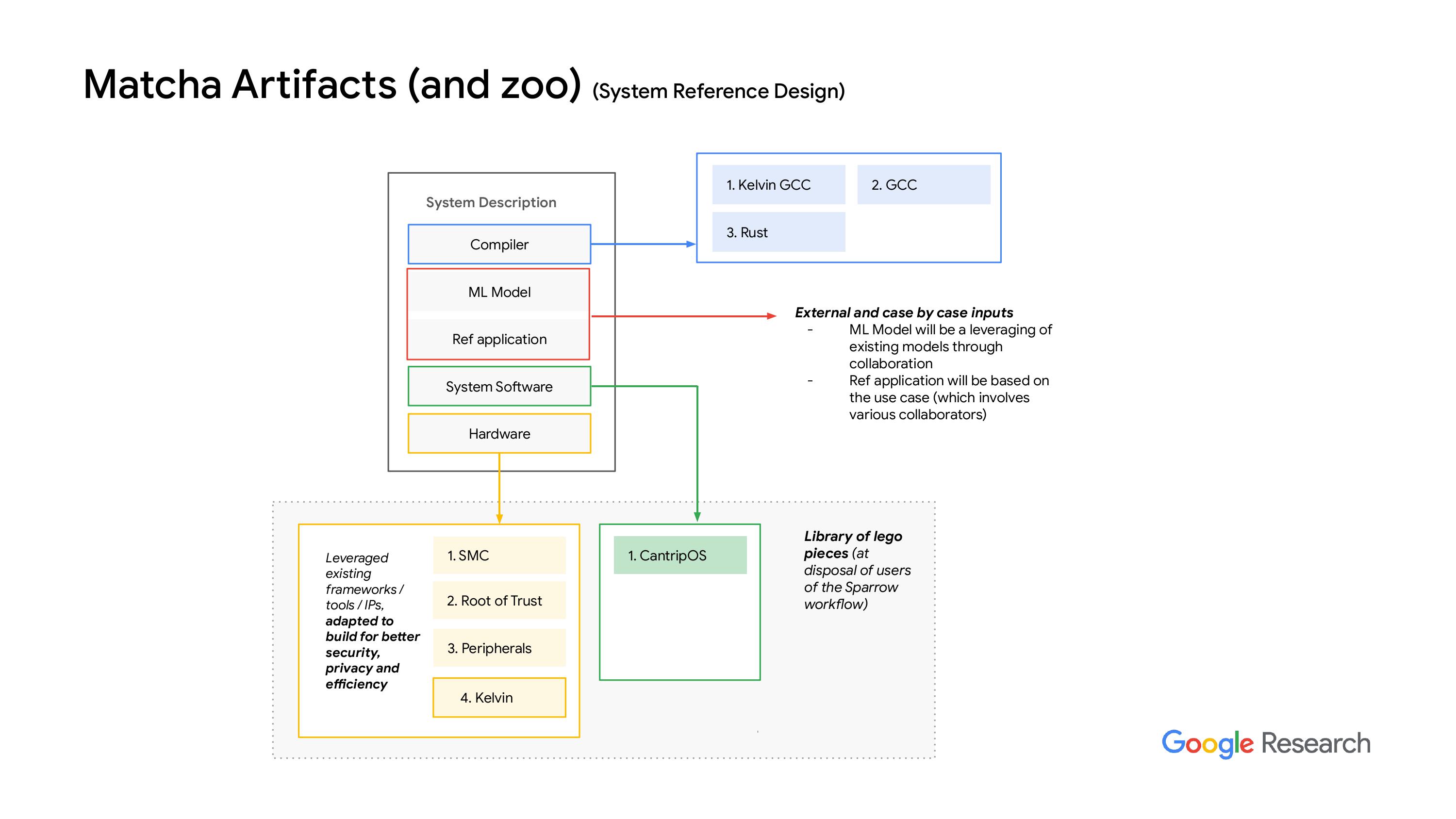
“我们现在在做一个环境感知传感能力子系统,最初我们叫它 Matcha,这个名字是基于OpenTitan 的,因为显然他们有‘ear gray’,而我们有 Matcha。我们还没想好下一个名字,如果有人有好主意的话,欢迎告诉我们。这个项目是我们把很多来自 OpenTitan 的开源组件整合在一起,并进一步提升这个能力。如果你们想要了解更多细节,可以在之后再聊。”这次会议主要是讨论一个系统,这个系统完全能够进行环境感知,配备了内部编码功能和内置的ISP。Sam会详细讲解这个系统软件的构建方面,这使得这个芯片既能作为环境感知的集成电路,又能作为音频、IMU传感器和相机的第一阶段令牌化工具。我们还与一个知识产权合作伙伴合作,开始开源知识产权组件,而不仅仅是现有的那些。
“我们可以在OpenTitan中使用,也有我们自己开发的,预计到11月时会有更多详细信息。就像我们之前提到的,我们有各种模拟工具和系统描述,此外我们还有一个组件和IP库,从硬件和软件的角度生成模型。而且,萨姆会进一步详细介绍系统软件。总之,目前我们具备所有工具。”我们计划在11月份开放所有源代码,从那时起我们会以开放的方式进行开发。我们快要在10月份完成第一颗芯片的测试,目前所有的东西都在FPGA上运行。我们很快会给你们展示一个演示,这是为了RT仿真我们的系统代码设计过程而开发的。我们的FPGA仿真了片上系统的IP,这是验证我们代码设计过程中的一个关键步骤。在这个演示中,我们将展示基于图像的机器学习使用情况。这是Nexus主板,我们把相机和显示器连接到这个主板上。相机数据会被传输到Nexus主板,然后再流到显示器上。我们还通过U和spy接口把NEX主板连接到主机。主机会监控并查看Nexus主板上的相机图像。我们建立了一个安全核心、系统管理核心和ML核心。安全核心是引导程序,用来启动SMC核心和ML核心。SMC核心则初始化显示器和相机,你还可以设置一个中断。处理相机模块的程序一旦图像帧在内存中准备好,相机模块就会发送一个中断信号给SMC核心。这个中断处理程序会通知ML核心开始计算当前的分数。中断处理程序也会在分数计算完成后将图像帧打印到显示屏上。下面是实时演示,摄像头实时播放在显示器上,而H机器的得分展示在上面,当前得分为零和一。

每个得分的范围在-128到127,得分越高,一个人出现在镜头中的可能性越大。得分为零意味着镜头视野中没有人,而得分为一则表示镜头中出现第二个人。如果镜头视野中没有人,两者得分都会非常低。现在镜头中有一个人,得分从负数变成了正数,而且得分很高。即使这个人移动和转身,得分依然保持很高,这说明镜头中有一个人。”我们现在在摄像头的视野中看到了两个人,正如我们所看到的,他们的得分都是零和一个,但都是正数,而且很高。这意味着摄像头视野中的这两个人成功被检测到了。正如 Kai 所说的,我接下来要聊的软件部分是一个更大项目的一部分,你需要明白这部分是为了我们要交付的目标专门设计的,所以这不是一个通用系统,但我们确实有一些通用的方面,希望这些能方便大家重复使用。
System-on-Nexus-FPGA
Fuchsia 社区小编注:上面开场是是 Kai Yick 介绍的 CantripOS 相关背景项目,部分关键词:Project Sparrow, OpenTitan, TockOS, bloaty, CAmkES 等等;下半部分是 Sam Leffler 介绍的 CantripOS

右上角是 Sam Leffler 大佬本人

拉近来看幻灯片

“另外,Kai 提到的硬件有三个核心,一个是安全核心,运行得很好,来源于 OpenTitan,提供了信任根,启动系统,同时也提供了一些其他服务,不过我就不多讲了。然后是系统管理核心,今天讨论的重点就是这个,它是用 SL4 作为内核的,内核之上有用户空间,全部用 Rust 写的。
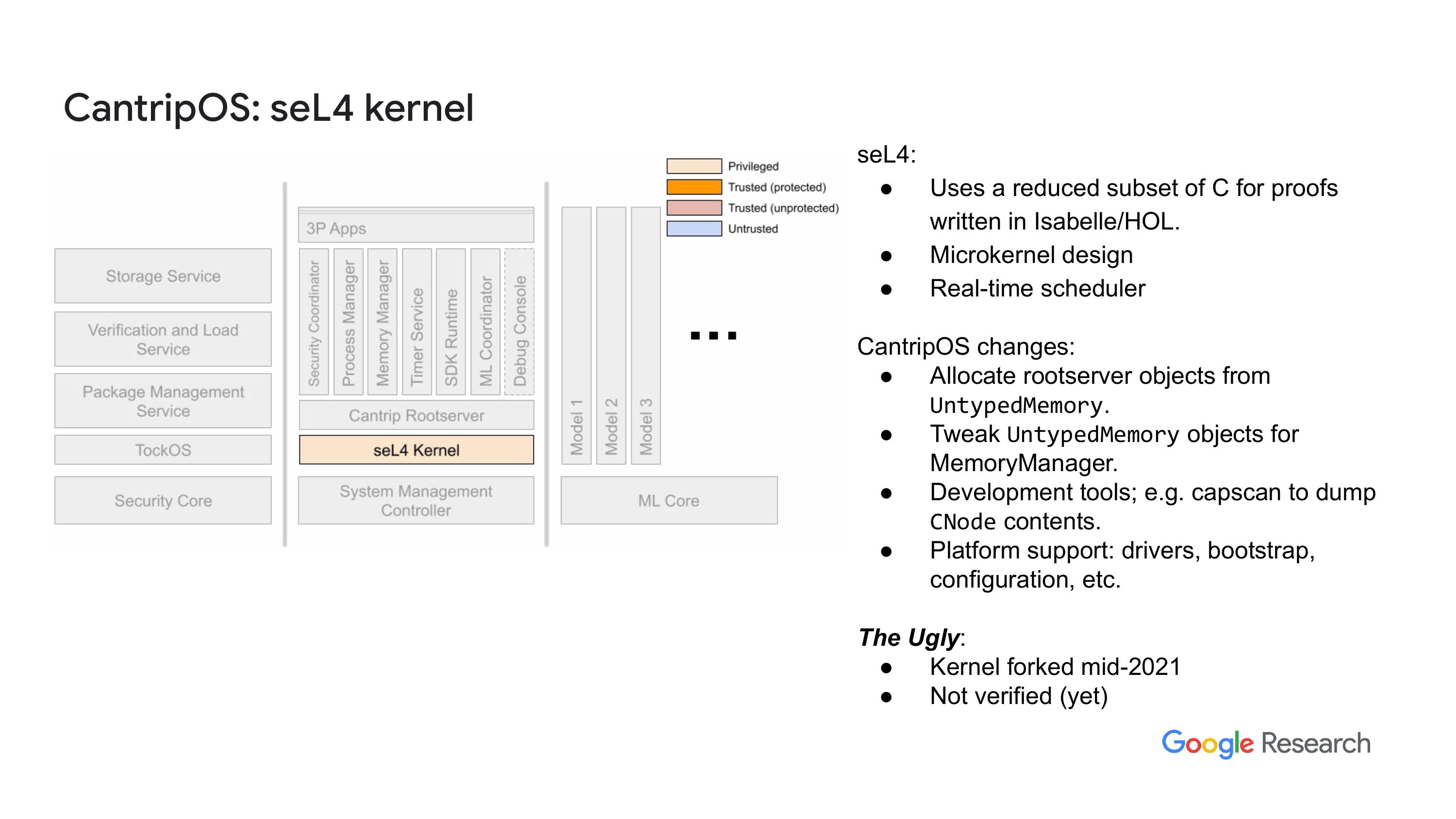
“我会尽量保持宏观来介绍 CantripOS。你如果去看网上的幻灯片,会发现里面有一些额外的幻灯片,深入介绍了某些方面。如果你觉得有什么不太明白的,或者想要更多信息,可以先看看幻灯片,看看有没有提供详细信息的部分。所以,这个幻灯片就展示了 CantripOS 的关键要素或者主要部分。”“嗯,有些人可能听说过这个名字叫 KataOS,但之前有人已经用了这个名,所以我们不得不重新命名。其实,这样最大的副作用就是我们失去了 Git 历史,因为我们不得不更改仓库的名字,现在我无法查看之前的版本历史。提到这个只是因为,正如 Kai 说的,年内我们会开放所有的源代码,而到目前为止,我们一直在发布一些代码快照。”我们得按照 Google 的要求走这个流程,以确保不会泄露内部信息。实际上,我们是把数据复制出来,然后你在 GitHub 上看到的内容,比如 git 仓库里,会有一个 git log,显示合并的提交记录之类的。所以,你可能无法完全了解开发过程是怎么进行的,以及为什么做出了这些决定。不过,当我们将所有东西开源时,希望所有的历史记录都能保留下来。这就是我提到这个的原因。
“正如我在这里提到的,你们可以看到有很多事情我会一个一个来讲。我要试着讨论一下这些内容。关键是,正如我之前说的,这一切都是开源的。我们用了 seL4,就像我提到的,实际上就是标准的 seL4 。可惜的是,在我加入这个项目之前,负责内核修改的人在做我们平台的支持时,添加代码的时候有点儿粗暴,所以我们失去了一些正常的东西。”对RISC-V 32 位系统的支持,内核基本上是一个分支,所以它相比上游内核稍微滞后一些。
我会定期检查,特别是在出现问题的时候。不过,除了这个分支和没有向前发展的情况,我们还做了一些对我们需求至关重要的本地修改。你要记住,我们的目标平台是一个 RISC-V 核心,seL4 是一个 RISC-V VI 核心,而且我们的内存只有 4MB,实际上我们还希望进一步缩小这个尺寸。"内存占用我稍后会详细说明。为了支持这一点,我们对内核做了一些改动,以便回收根服务器运行时占用的内存。正如我所说,我们的系统是基于 CAmkES 代码,因此内核会启动并初始化系统,使用的就是我们的根服务器,实际上是我们自己重写的 capd loader。然后,在根服务器运行并实例化 CAmkES 组件之后,我们会把根服务器使用的所有内存都回收回来。这就是情况。"
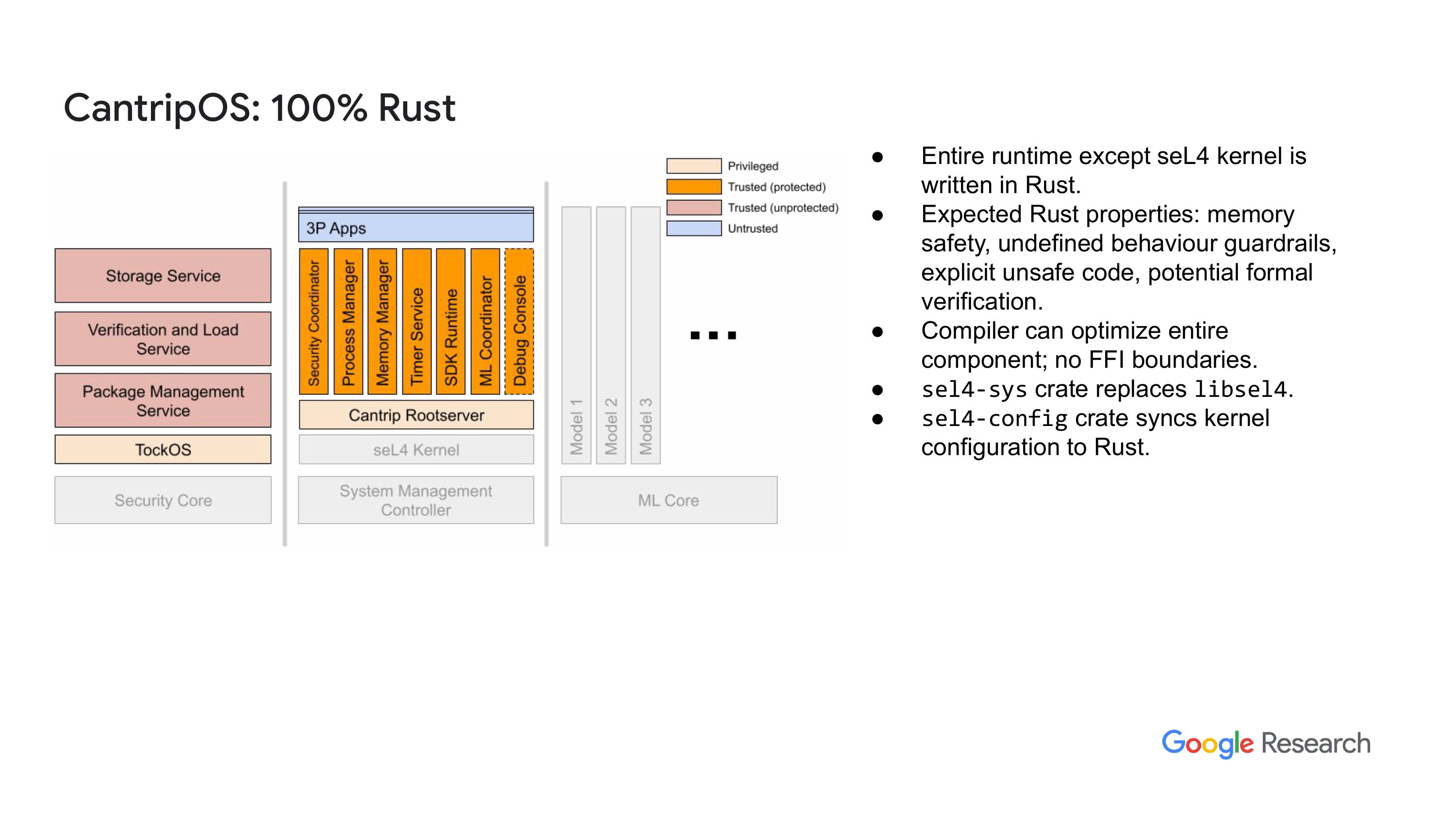
这对我们来说很重要,正如我提到的,用户的运行时是100%用Rust的。现在,写系统软件的人好像都想用Rust,这语言特别受欢迎。它有很多重要的特性,尤其是内存安全。还有一些其他我列出来的特点。我们逐步把我们的系统迁移到现在的状态,运行时已经100%是Rust了。这样做的初衷是,当我们开始这个系统时,我们的工作就是这样开始的。

“我用的是 CAmkES 代码,生成了这些‘胶水’代码等等,给编译过程提供了一些界限,优化器实际上不会越过这些界限。现在切换到100% Rust后,编译器可以从栈的顶部到底部看到所有内容,能够进行优化。比如说,前几天我在做一个优化,把一些东西移到Flash上,链接时优化器发现其实我并没有真的…”
"提到某些符号的数据,只需要把整个符号集去掉,像这样,这个占了半兆的压缩包就消失在了capl loader图像里,我根本不需要添加什么配置选项。这一切的结果都是因为,至少在这个案例中,其余的编译器能够从头到尾看到所有东西。所以,在用Rust编写代码时,另一个关键点是我们需要一些胶水代码来把它们联结起来。"内核配置到 Rust 运行时,这样你就能获取所有该有的东西,比如你有没有在用 MCS 之类的。所以我们有一个 crate,可以在构建过程中同步配置。你必须先构建内核,然后从构建产物中提取出配置文件,把它转化为 Rust 特性,用来驱动 Rust 的编译过程。正如我说的,我们还是在使用 CAmkES,至少还用了一些部分。我们一开始就是一个普通的 CAmkES应用,生成的 C 代码是通过 CAmkES工具生成的。
工具方面,我们随着时间的推移,逐渐去掉了接口规范,把原来的模板替换成了新的模板,这些新模板生成Rust代码,这就是我们实现100%使用Rust的过程。其实这个过程做起来很简单,不过一开始花了很多时间调试,因为我对 CAmkES 里某些东西的工作原理理解错了,按照我认为的方式去实现,而不是它们实际的运作方式。所以我经历了一些。在调试的时候遇到了一些非常细微的问题,比如在启动时出现的那些问题。此外,我们把代码从C转到Rust,这样就能放弃4个运行库,尤其是musl库,它实际上是个内存大户。我们这边还添加了一些必要的东西,很多是为了减少内存占用,像线程抑制和中断请求合并这些都是为了达成这个目标的。我会详细讲讲这些东西。

“嗯,后来我想说,我们在做这个 CAmkES 工作的另一个原则是,我们想确保……我其实不太同意CAmkES所做的一些事情,就是我不想要任何自动生成的代码,尽可能的话我只希望CAmkES能做资源分配、全局资源的分配和打包,然后就不要管其他的。所以如果你看看我们生成的代码,你会发现基本上只有一些定义,然后……”
下面是幻灯片23-27,实际 Sam Jeffler 演讲中似乎是跳过的



从这里开始介绍 cantripos-root-server

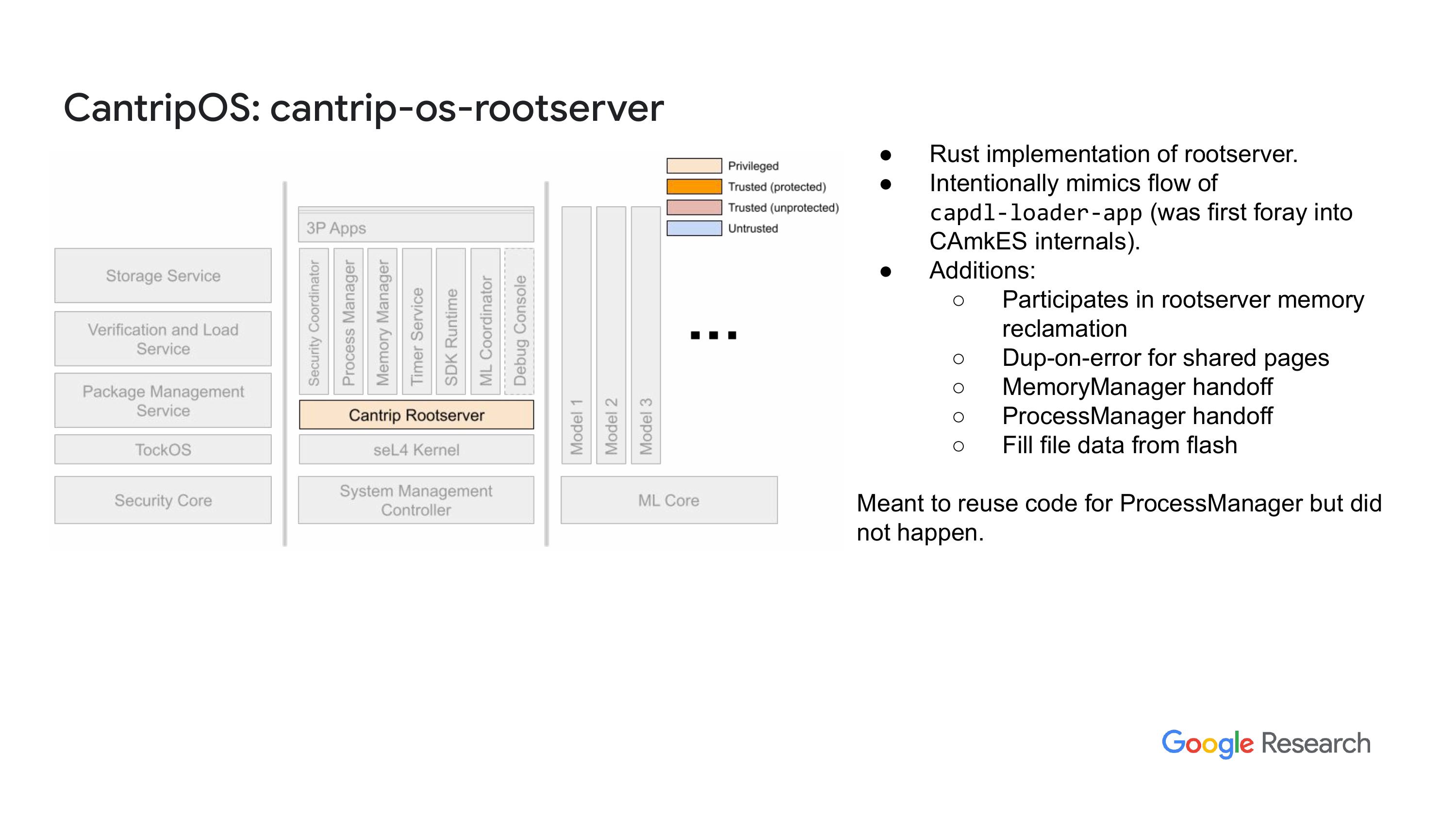
“库支持运行时功能,你其实可以随心所欲地写东西,完全不需要用模板。就像我说的,我们有自己版本的根服务器。这是我对Rust的第一次接触,感觉就像直接跳进了深水区。我当时非常担心会出错,很多东西也没完全搞懂。所以我最开始做的是将C代码忠实地重写成Rust,然后随着对语言的理解加深,我开始慢慢偏离这个方向。”
“然后呢,嗯,你知道的,正如我之前提到的,我们有这个记忆回收的过程,嗯,根服务器必须参与其中。还有一个有趣的点,就是我做了一个可能很有趣的事情,就是有一些共享内存页的机制。如果你有一个在cap L中指定的页面,它被多个组件使用,嗯,加载器要启用一个标志,然后加载器会用这个标志来复制所有可能以这样的方式使用的能力。"
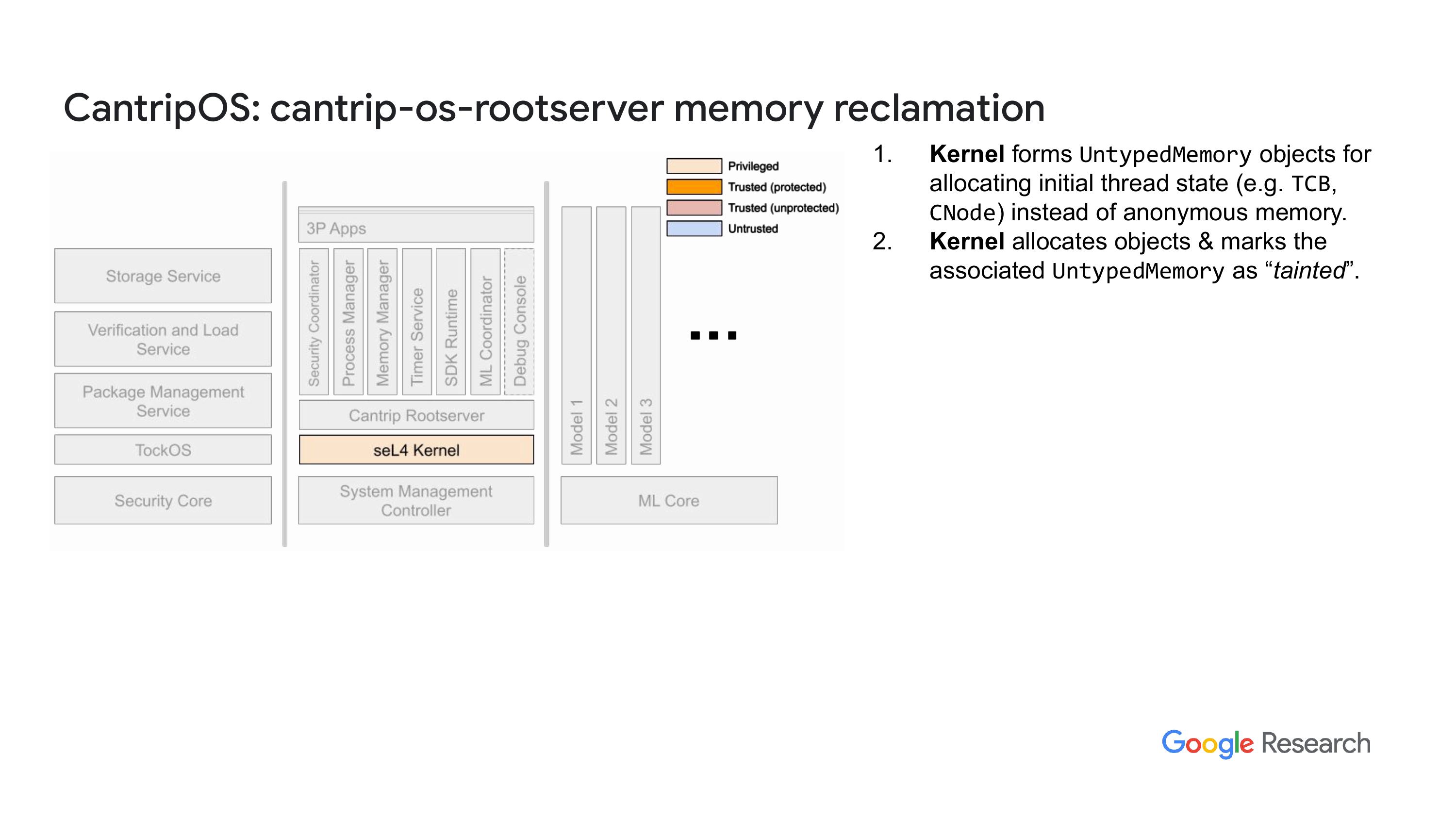
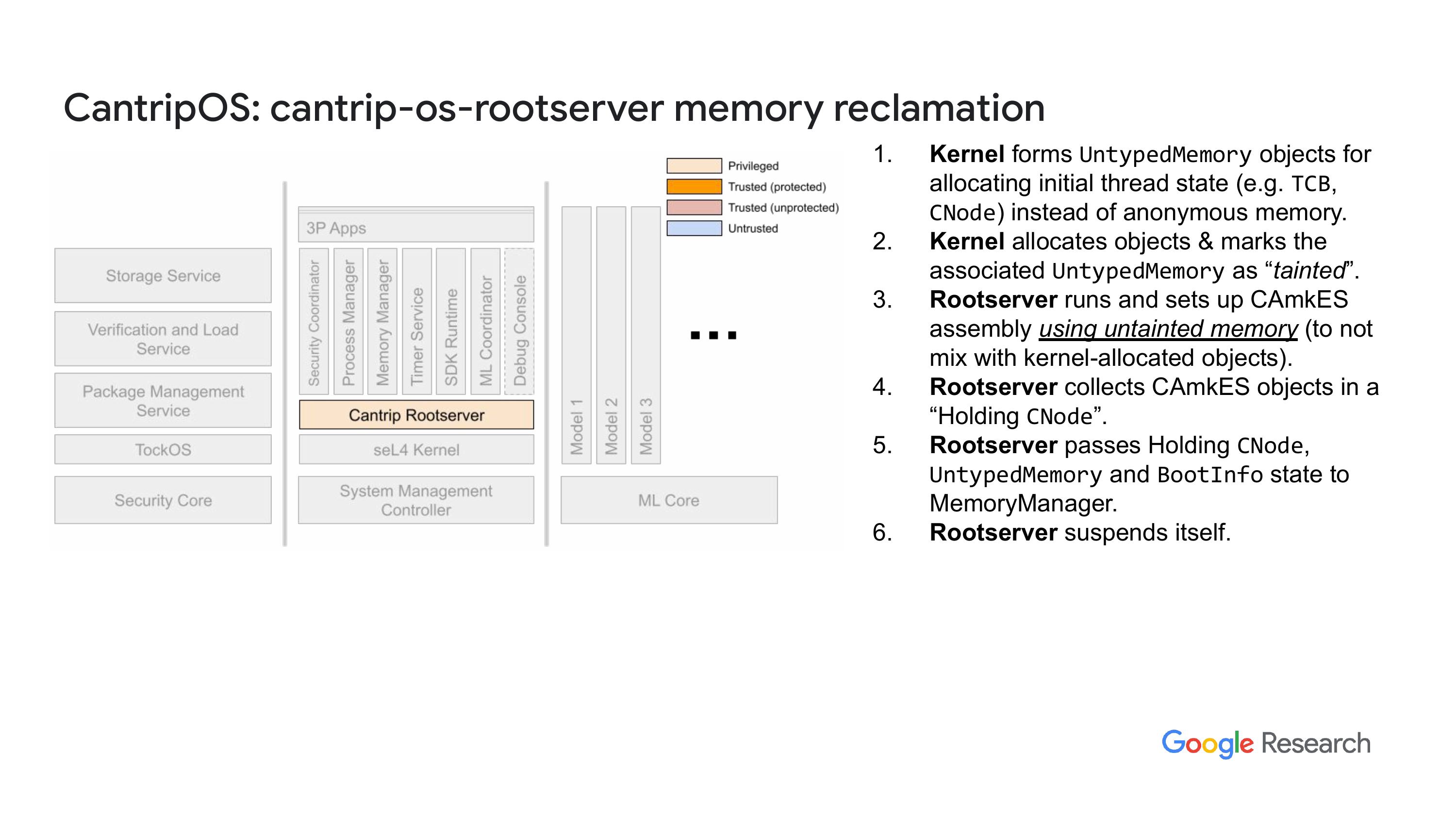
“这是关于版权的一些事,我会检查一下页面的映射,结果收到一个错误提示,说这个已经在使用中。那么我就会复制一份。这样做的原因是可以显著减少根服务器中某些表的大小,所以,不需要原本数据表的两倍大小,只需多个50就可以了。此外,跟我们根服务器相关的其他特定细节在这里列出来了。我还想提一下,这算是我第一次接触这块,我当时有点天真。”我之前在幻灯片里提到过,我们会动态创建应用程序和新线程之类的。我当时想到,要写一次这些代码,然后就能重复利用。结果发现我想错了。起初我想着有大计划,结果后来发现并不是那么回事。
就像我说的,我会逐个讲解这些组件,聊聊它们的功能,简单概述一下。
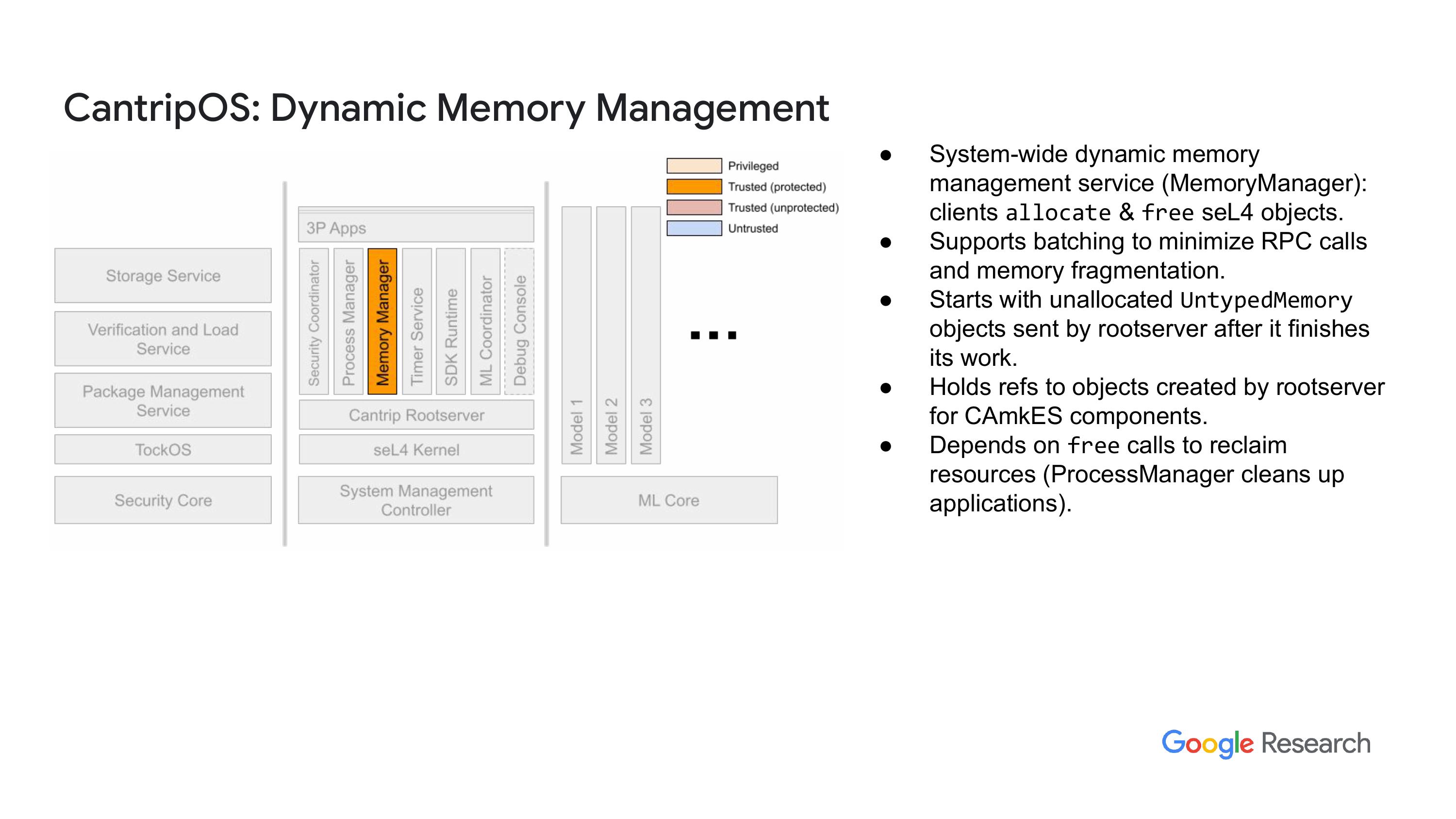
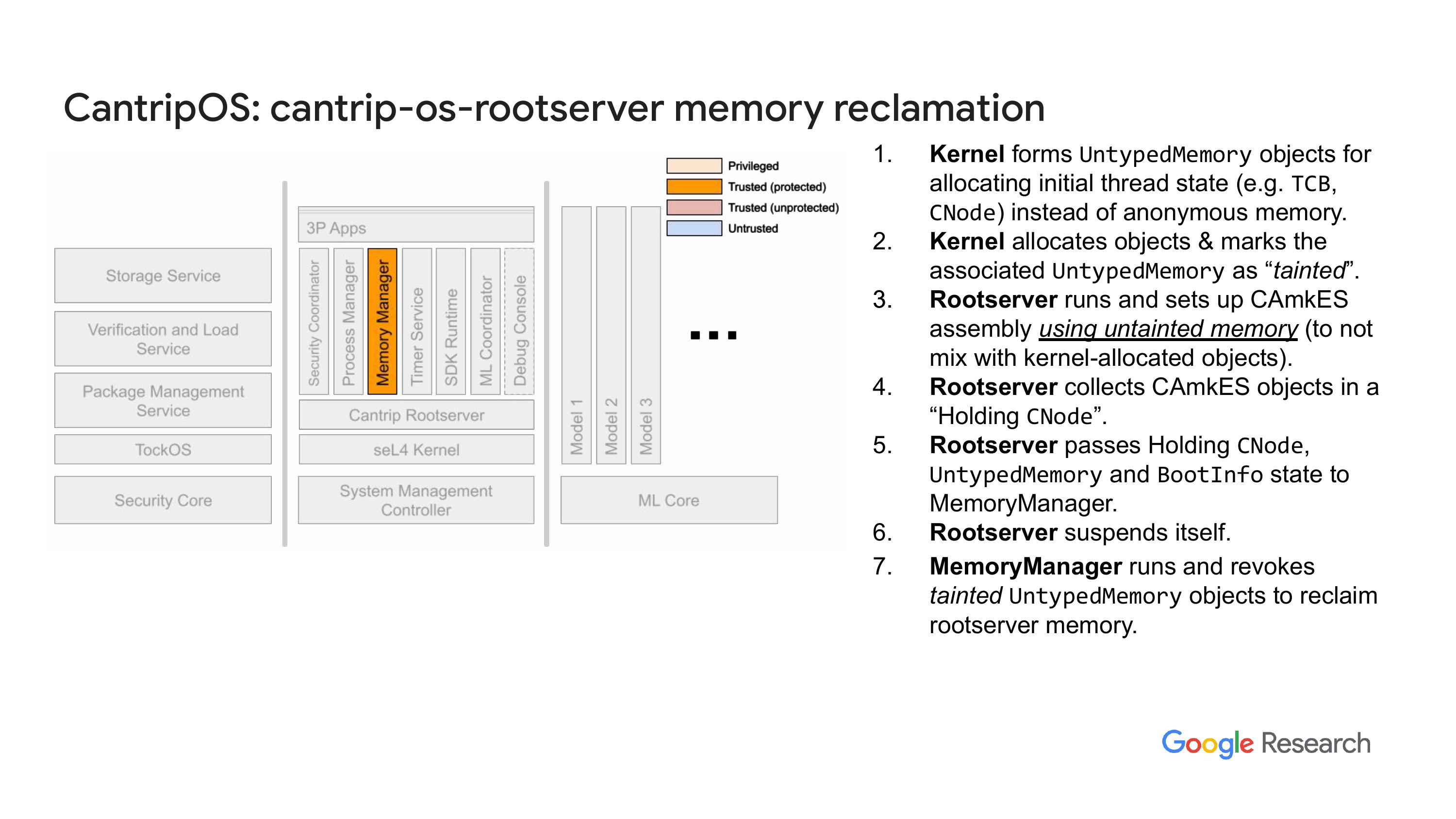
接下来要说的是内存管理器,我们会进行系统范围的动态内存管理。管理方面,目前已有一些 SL4 库可以在特定组件内使用,但这些库不一定能跨组件使用。我们的做法是提供一种服务,你可以请求这些对象通过 RPC 消息返回,返回的对象会附带 RPC 消息的相关功能。这让你可以分配内存并创建小于一个页面的对象,你根本不需要直接去处理非类型内存,只需直接获得这些对象就行了。而且,你可以从任何具有权限的进程中做到这一点。与内存管理器交流一下吧,我想我并没有提到这些幻灯片里,我们把系统里不同的组件和部分分类,看看我们给它们多少信任,以及它们是否在保护模式下运行,是否有内存管理的边界和保护措施。这个主要是在讨论区变化比较大。所以左边是安全公司,这里是安全管理控制(SMC),这边是机器学习核心。总之,内存管理器就是这样的一个东西。
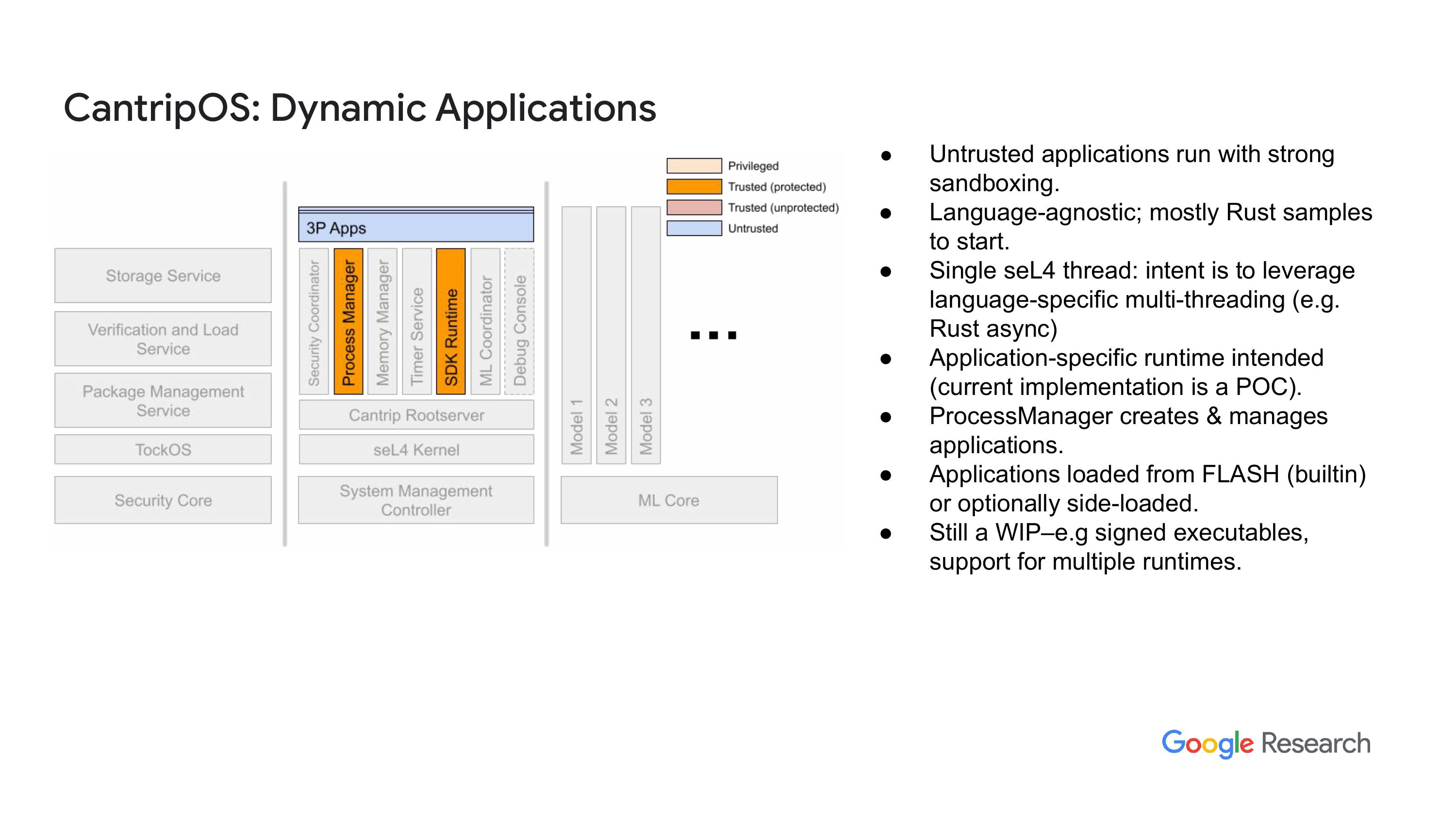
“嗯,说简单点,对我来说,写一个好的内存管理器真的是太难了,尤其是因为上级给的无类型内存的限制。现在我们必须要求每个人在释放对象的时候告诉内存管理器去释放这些对象,这样我们才能保持一个中央的状态数据库。我考虑过如何改进这个问题,未来我们可能会有一些变化,但现在我们真的很难去做这些事情。”我们做了一个优化的内存分配器,其实就是一个很简单的分配器,完全满足我们的需求。正如我之前说的,能够运行动态应用对我们来说很重要。这些应用可以是从系统镜像中自带的包里加载的,也可以是通过串口、网络等方式侧载进来的。这些应用都不可信,所以我们会把它们放在沙箱里。正如我提到的,我大大简化了这些应用的环境,所以它们和语言无关。他们是单线程的,我们的期望是,如果你需要多线程的话,就自己引入你语言中喜欢的运行时包来实现多线程。但可能会发现这个实现有点局限,反正我们还在不断改进中。同时,也要记得我们有一些特定的目标,需要支持某些应用程序。最终的目的是,安全部门会验证可执行文件的签名,同时也会进行其他验证。
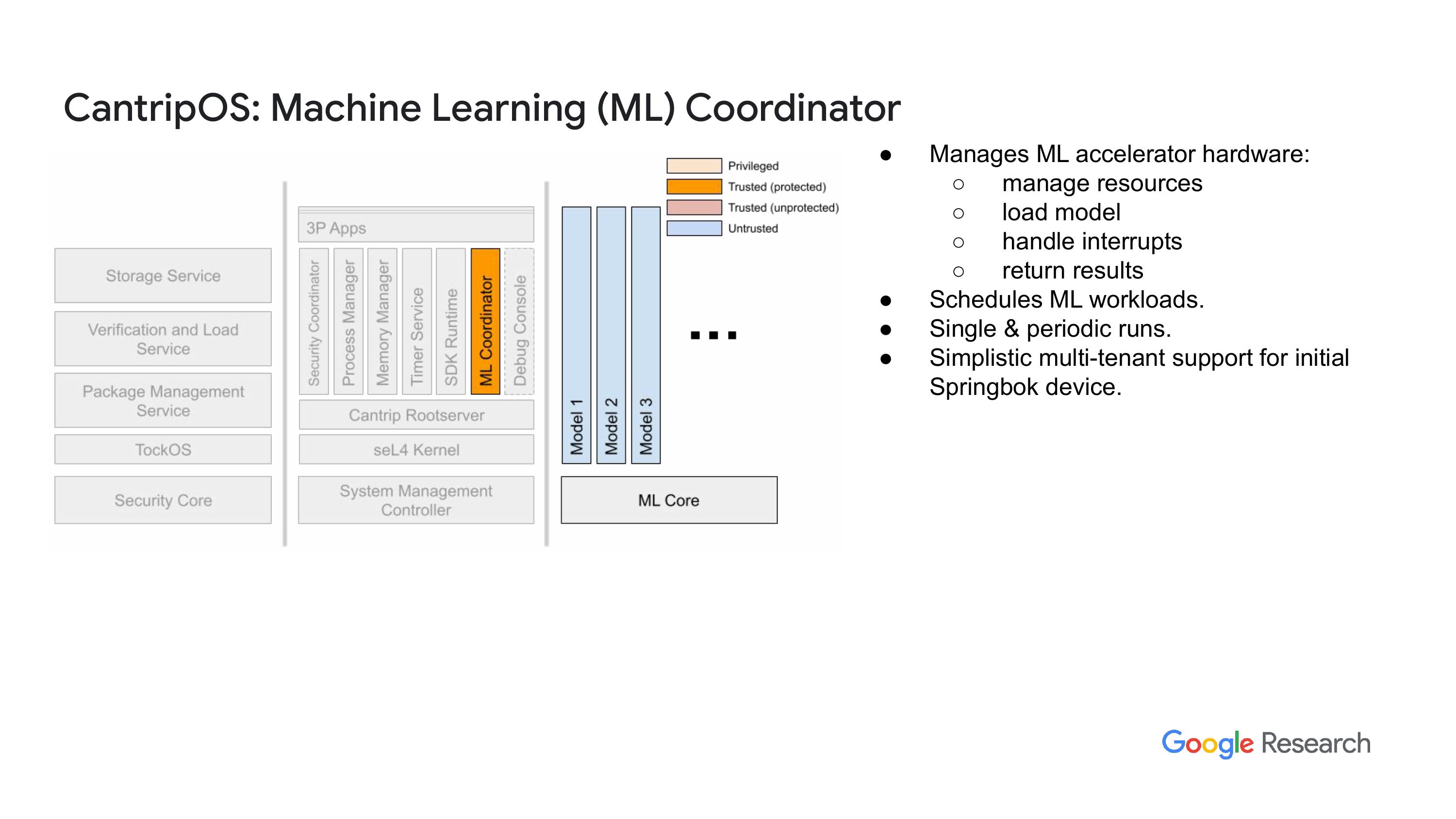
启动过程中的另一个服务是机器学习协调器,这只是一个通用的作业调度器。它在机器学习核心的内存管理方面有一些智能。我们实际上经历了多个版本的机器学习核心,我们是有两个还是三个?我在试图弄清楚马拉穆德(Malamud)的情况,哦是两个。好的,所以最初的,你如果仔细看看代码,能看到两个不同设计的痕迹,其中一个叫做springb,这个设计更雄心勃勃,是基于RISC架构实现的。
“五个向量核心V风险,风险五个向量指令集扩展,虽然它有窗口化的内存管理单元,这样可以支持多租户,能够同时在机器学习核心中加载多个ML模型。我们经过设计讨论后得出结论,认为更简单的设计更符合我们的需求。因此,现在系统还支持另一个核心,我们称之为Kelvin,它一次只支持一个任务运行,语义上更简单,比如说如何处理故障。”还有像这样的事情,另一个人工智能正尝试变得非常通用。嗯,这个要简单得多,所以机器学习协调员负责加载模型、运行模型、调度模型,处理模型失败的情况,并向应用程序报告结果等等。
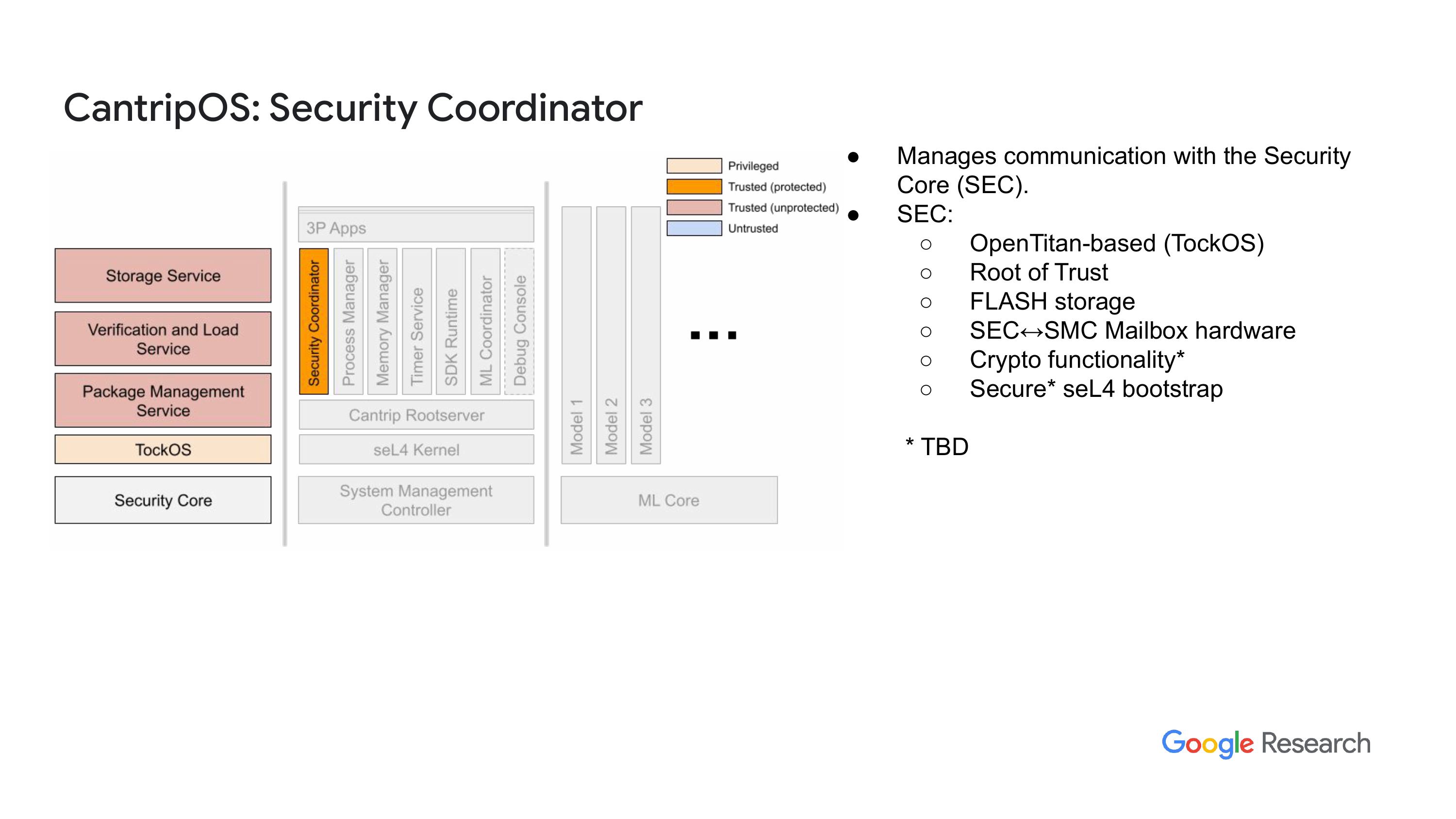
嗯,我最后要谈的是安全协调器(Security Coordinator)。这个软件是在SMC上运行的,在 seL4 上层,并与OpenTitan和安全层进行通信。目前没什么太多事情要做,因为OpenTitan 安全核心负责启动系统,完成后它的主要作用就是提供对安全核心存储器的访问。所有需要保护的关键资源都被隐藏在安全核心的另一侧。所以当我们想要像将应用程序加载到内存中这样的操作时,就必须去安全核心请求它从闪存中把资源拿回来。除此之外,安全核心就没什么特别的功能了。目前这方面的进展不算太多,嗯,最终它具备了所有这些在 Open Titan 中的加密功能,但早期的时候这些功能还没准备好让我们使用。现在这些功能已经到位了,我们需要整合这些功能。
这就是 CantripOS,它是一个系统,是运行时,搭建在这些基础之上的。我想简单谈谈我们在开发这款软件过程中的一些工具,以及为什么在某些方面这些工具是有意义的。在一些情况下,我们为什么要花这么大劲呢?

sel4gdb 是一套工具,由 Ant Micro 开发。这个人名字叫 Marcine,他的姓是波兰语的,我不确定能不能正确发音,所以我就不尝试了,反正 Marcine 是个非常棒的程序员。他做过很多事情,包括根服务器的内存回收,还做了sel4gdb 系统。目前这个系统完全依赖 Renode,因为它需要 Renode 来完成一些操作。在这个过程中,我们捕捉 Contex 切换,然后利用这些信息来生成从线程名称到 TCB(线程控制块)等的映射表。这为调试和开发软件提供了一个非常重要的机制。这样你就可以通过线程名称进行引用,可以在进出内核时设置断点。比如你可以设置在返回用户空间时停止,这样当你从内核返回到用户空间时,第一条被执行的指令就会触发断点。可能你并不清楚自己想进入哪个线程,但你可以这样操作。设置符号断点的时候,不仅仅是针对 gdb 知道的线程,而是针对每个线程,我们大量使用这项功能,所有这些都是可以实现的。
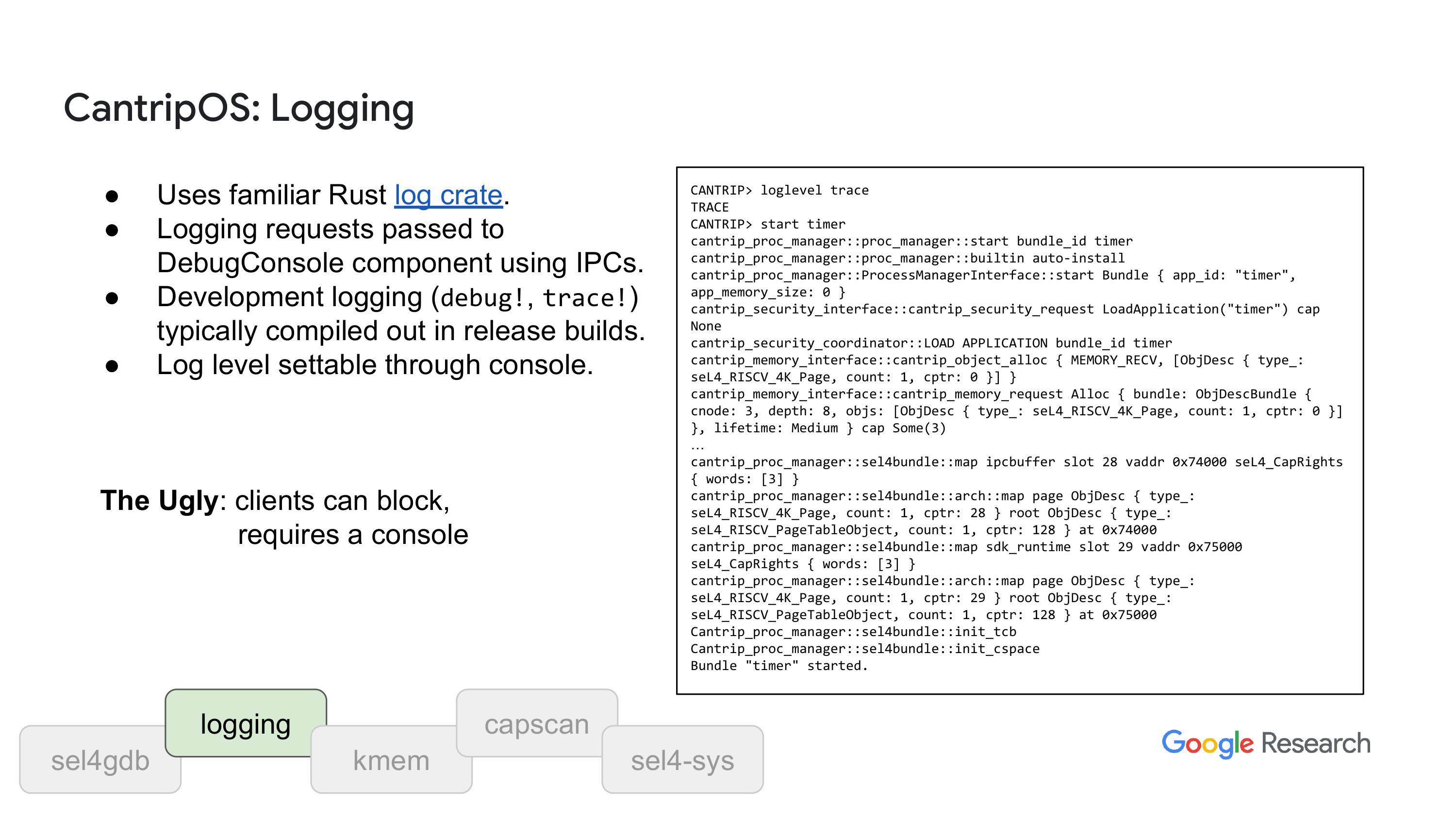
我还想提一下日志记录,我们直接调用 Rust 的 log 库,通过 IPC 消息传递所有信息。在正常运行时,我们有一个控制台,这个控制台的线程会接收这些消息,然后发送到 UR,这样你就可以看到这些信息了,如果你有 UR 驱动的话。最后我们会讨论一下支持哪些平台,但我还有多少时间呢?有很多时间,不过,要是没有控制台的话,我们可能需要一些其他的东西,可能是一种圆形的缓冲区,方便我们把东西先放进去,以后再手动提取。因为在大多数部署这个系统的情况下,是没有控制台和串口的,所以这就是正常的情况。不过这里面确实有很多不太好看的地方,真的需要重新设计。就像你看到的那样,但你大概能明白我们通常的做法是什么。当我们写代码的时候,我们会把一些追踪请求和日志记录加到代码里,以提供关于功能如何运行的重要信息。然后我们可以在调试版本中利用这些日志,看看程序是怎么从这里到达那里等情况的。而在发布版本中,我们会优化掉这些日志,节省空间,但有时候这不是我们想要的效果,所以我们有机制可以在发布版本中开启这些日志。

Memory Footprint Tools:
另一个我们在开发工具方面进行了大量工作的重点是减少内存使用。足迹嘛,你得明白,不仅资源支出(capex)跟内存占用有关,比如你买芯片要花多少钱,这也会影响到你要分配多少内存来运行系统。而且还有电力方面的问题,你知道,系统的内存越多,所需的电力就越大,电池的消耗就越快等等。然后,Ring刚推出了一个非常有趣的摄像头,就是一个电池驱动的门铃摄像头。这段话的意思是:“这个东西具备物体检测功能,并且由两颗AA电池供电,可以工作两年。所以他们的目标跟我们的确很相似,他们也做了类似的事情。我要提到这一点是因为,若想达到这些目标,你真的需要关注你系统中运行的所有东西,包括内存。我们花了大量时间来调整系统,改进各个方面,增加一些调节旋钮和配置参数,努力让系统变得更通用,从而减少内存使用。”这段话的大意是:“使用方面,比如说线程的成本很高,而且开销也很大。所以我们有一些机制来重新利用线程。比如说在一个组件中的控制线程几乎是从来不使用的。你可以说,我有一个接口线程处理某种RPC服务,但你可以选择不为它分配一个线程,而是把它放在控制线程里,这样就省掉了一个线程。类似的这种简单调整,实际上能带来很大的改善和影响,以及我们如何测量这个影响,我们有一些工具。其中一个工具是这个 kmem.sh 脚本,它实际上会查看 kmem.sh 工具生成的数据,并为每个组件提供一个详细的分解。如果有共享对象或者组件之间共享的对象,它会把这些单独列出来。而且它是知道这些的,因为它只关注真实的页面框架。当我们看下一个的时候,会发现这其实不是个很复杂的问题, km 脚本可以查看具体哪些页面框架被分配了。它能把所有的系统内存和系统对象的分配情况都给记录下来,这样你就能清楚地了解到整个系统的情况,这对于查找某个组件中意外的内存使用情况非常有帮助。此外,我们还用另一个工具叫做 bloaty,大家也可以在 GitHub 上找到它,我们来分析一下一个可执行二进制文件里最贵的部分。因为这些组件都打包成可执行的 ELF 文件,你可以用这个工具来分析它。我给你展示了一个例子。不过,使用这个工具需要小心,因为 bloaty 不太了解 CAPL 或 CAmkES 中提供的机制。比如说,栈的顶部和底部都有一个保护页面,这些其实是未映射的页面,但在这里会显示为分配的页面。这些工具很简单但是真的很有用,不过我们缺少的是能看到每个线程的堆栈深度,这样就可以调整堆栈大小了。还有一点也很有用,应该也很简单,就是为了减少根服务器的开销,你需要限制根服务器中数据结构的大小。但是这其实是个需要两次迭代的过程,你得先搭建好系统,然后启动看看情况。”好的,呃,首先要知道有多少个对象被实例化之类的,然后利用这些信息来调整你的数据结构。这是一个两阶段的工作,嗯,但应该可以自动完成。
Fuchsia 社区小编注:跳过几页幻灯片




嗯,最后一个跟编程相关的事情,我觉得就是我们所说的 Capscan。好的,谢谢,真的就是这些了。好的,我会快点说完,嗯,我快结束了。早些时候,当我在做能力传递的时候,嗯,我丢失了那个能力。我想做的就是搞清楚系统里哪个地方有这个能力。我本来打算写个简易的蠕虫,让它可以在所有组件之间游走,搜索能力的C表和C节点,但这太复杂了。所以我改成了做一个小机制,可以把C表的内容导出来。你给它一个C节点,它就会给你一份里面所有能力的列表,结果发现这个挺有用的。

很多人都看过这个。“我觉得尼克可能会稍后谈到 Syscall Wrappers ,但我就跳过这个了,这样我们可以聊聊 CantripOS 未来的工作了。

Kai ,你想上来吗?正如 Kai之前说的,我们正在努力把所有东西开源。
下面是 Kai Yick 介绍的:

所以我们计划在11月的时候开源所有东西,不过我们还没决定是要在RISC-V峰会还是在芯片联盟会议上发布。总之就这两个选择。”“我们计划在11月左右开放我们的整个代码库,具体是大概在11月初。届时会在谷歌开源博客上发布公告,并且跟我们的合作伙伴一起发布相关的媒体信息。我们还没有完全理清所有细节,现在还很早,但我们的目标是尽快在11月初发布。同时,我们也会提供一些例子,讲解如何搭建我们的整个系统,并在我们的Nexus平台上运行这套系统。对了,Nexus这个名字是受《星际争霸》的启发,不应该忽略这一点。”提到这点,嗯,不过我们还在和一所大学合作,看看能不能把这个系统定期地运行起来。因为我们希望大家能够在标准的环境中重现这些成果,无论是通过模拟器,还是在FPGA平台上。所以我们计划在一个尚未公开的网站上提供一些指导,帮助大家实现这一点。

正如我之前提到的,我们会直接开放主仓库,这样你就可以看到更多的成果和日志。
“项目的代码开源基本上会跟 Android 和Chrome类似,应该会放在一个 Gerrit的代码库里,你能用 repo 命令去操作它,因为里面有超过60个项目,所以我们希望你能利用repo命令,比如repo init之类的,把整个代码库同步下来。

好吧,正如你所见,我们专注于在特定的平台上运行。我快速在 qemu 上做了一个 aarch64 的树莓派实现。”为了展示怎么使用这个,嗯,大家其实还没怎么注意到,这也不奇怪,开始的时候可能会让人觉得有点难。不过,我们还有很多其他功能想继续开发。正如之前提到的,我们专注于那些需要比边缘计算更多处理能力的机器学习应用。在这方面,我们打算整合像 Project Oak 这样的东西,Project Oak是一个GitHub上的项目,它可以让你和一个可信的执行环境数据中心进行交互。“我们需要弄清楚一些网络方面的东西,所以我觉得差不多就是这样了,没时间问问题,谢谢大家,真是太棒了,非常感谢!
我会留点时间给大家问几个问题,首先举手的可以提问,谁都可以。
下面是 QA 环节
好吧,我会接受两个问题。
问题1: 如果当时有微型工具包可用,你选择使用的话,会减少多少麻烦呢?
Sam: 因为并没有生成代码,也没有多线程的部分,嗯,抱歉,它是用C写的,没错,抱歉,我可能说得太轻松了,不过肯定是有改善的,但是我觉得无论如何都有很陡的学习曲线,所以我也说不清楚这会带来多大优势。
问题2: 抱歉,关于OpenTitan那边有个快问题,目前是放在RX7板上,开放之后,如果跟大学合作的话,可以把它放到… 对吧?”
“zcu102 可以支持 Qs spf28 接口,这个方向和 OpenTitan 有什么关系呢?我觉得目前的 OpenTitan 确实可以在 ARX 平台上使用,不过我记得最近的版本好像是从 aex 平台升级到了 kex 平台。我不太记得具体是哪个版本了,关于 siling death 支持方面也是。对了,RTL 是支持 quadpy 的,我以为他是在问 qpy,没错,我们的平台确实有这个功能,所以我们的 RTL 可能是……”这个跟你从OpenTitan直接得到的东西稍微有点不一样。我们是基于OpenTitan进行开发的。可能也可以回答你之前问的一部分问题,虽然我可能没听清楚。不过,等我们在OpenTitan的基础上建立所有基础设施后,我们可能会需要比OpenTitan要求的更大一些的FPGA。我们会在网站上提供相关规格。好的,谢谢,非常感谢!
引用:
















Comments